
程序设计基础(I)总结
程序设计基础(I)总结
本文档是对2024年10月09日(星期三)及之后程序设计基础(I)课程的总结,仅供参考。
课外题目收集
本栏内收录部分其他班同学问到的课外题目,不一定完整,供大家参考。
高精度加法
[题目描述]
输入两个正整数$x_1, x_2$,求$x_1+x_2$
$(1\leq x_1, x_2 \leq 10^{99})$
[输入格式]
两个整数$x_1, x_2$,中间用一空格分隔
[输出格式]
$x_1+x_2$的值
[样例输入]
9000 1000
[样例输出]
10000
思路: 通过字符数组读入后,将其转存至整型数组中,模拟手算,因为不涉及负数判定,没有需要特判的地方。
#include <iostream>
#include <cstring>
using namespace std;
const int Length = 101;
void v_String_to_Int(char s_Str[], int n_Num[]);
inline int n_MAX(int n_NumA, int n_NumB) {return n_NumA > n_NumB ? n_NumA : n_NumB;}
int main()
{
char s_Num1[Length];
char s_Num2[Length];
int n_Num1[Length] = {0};
int n_Num2[Length] = {0};
int n_Result[Length] = {0};
int n_MaxLen;
cin >> s_Num1;
cin >> s_Num2;
n_MaxLen = n_MAX(strlen(s_Num1), strlen(s_Num2));
v_String_to_Int(s_Num1, n_Num1);
v_String_to_Int(s_Num2, n_Num2);
for (int i = 0; i < n_MaxLen; i++)
{
n_Result[i] += n_Num1[i] + n_Num2[i];
if (n_Result[i] > 9)
{
n_Result[i] -= 10;
n_Result[i + 1] += 1;
}
}
if (n_Result[n_MaxLen] >= 0)
{
cout << n_Result[n_MaxLen];
}
for (int i = n_MaxLen - 1; i >= 0; i--)
{
cout << n_Result[i];
}
return 0;
}
void v_String_to_Int(char s_Str[], int n_Num[])
{
int n_Length = strlen(s_Str);
for (int i = 0; i < n_Length; i++)
{
n_Num[i] = s_Str[n_Length - i - 1] - '0';
}
return;
}
分数最高的学生
[题目描述]
输入若干学生信息(包括学号、姓名、C++整数成绩),计算其中的分数最高的学生,并输出该学生的信息。若有多个学生获得C++最高成绩,则输出先输入的学生信息。
[输入格式]
依次输入若干学生信息(以学号、姓名、C++成绩为顺序),其中学号和C++成绩是正整数。若输入的学号非$-1$,则继续输入;否则停止输入。
[输出格式]
依次输出C++成绩最高的学生的学号、姓名、C++成绩,之间用空格分隔。最后不要有多余的空格。
[样例输入]
1 张三 80
2 李四 85
3 王二 85
-1
[样例输出]
2 李四 85
思路: 使用结构体存储读入的数据(其实也可以不用,只不过按老师要求要这么写),并记录最先读到的最高成绩的同学的下标,直接输出即可。
#include <iostream>
#include <cstring>
using namespace std;
const int SIZE = 101;
struct Information
{
int Number;
string name;
int score;
}I_Info[SIZE];
int main()
{
int n_Cnt = 0;
int n_MaxScore = -1;
int n_MaxIndex = 0;
while (1)
{
cin >> I_Info[n_Cnt].Number;
if (I_Info[n_Cnt].Number == -1)
{
break;
}
cin >> I_Info[n_Cnt].name;
cin >> I_Info[n_Cnt].score;
if (I_Info[n_Cnt].score > n_MaxScore)
{
n_MaxScore = I_Info[n_Cnt].score;
n_MaxIndex = n_Cnt;
}
n_Cnt++;
}
cout << I_Info[n_MaxIndex].Number << ' ' << I_Info[n_MaxIndex].name << ' ' << I_Info[n_MaxIndex].score;
return 0;
}
这份代码不严谨的地方在于题目未给出可能的数据规模,所以这份代码在数据量较大时可能会发生运行错误,更好的做法是每次只记录是否有更高成绩的同学,优化后的代码如下:
#include <iostream>
#include <cstring>
using namespace std;
int n_Input_Number;
string s_Input_Name;
int n_Input_Score;
int n_Max_Score_Number;
string s_Max_Score_Name;
int n_Max_Score;
int main()
{
while (1)
{
cin >> n_Input_Number;
if (n_Input_Number == -1)
{
break;
}
cin >> s_Input_Name >> n_Input_Score;
if (n_Input_Score > n_Max_Score)
{
n_Max_Score_Number = n_Input_Number;
s_Max_Score_Name = s_Input_Name;
n_Max_Score = n_Input_Score;
}
}
cout << n_Max_Score_Number << ' ' << s_Max_Score_Name << ' ' << n_Max_Score;
return 0;
}
课前代码练习
2024-10-09 $A+B$问题
[题目要求]
定义两个字符形(char)变量$a = 1,b = 2$,输出这两个字符形变量之和的值。
[输入说明]
无
[输出说明]
输出这两个变量之和的值。
[样例输入]
(本题无输入内容)
[样例输出]
(写出正确的代码后运行即可得到)
不难写出这样的代码:
#include <iostream>
using namespace std;
int main()
{
char a, b, c;
a = 1;
b = 2;
c = a + b;
cout << c << endl;
return 0;
}
那么运行代码后会得到什么结果呢?
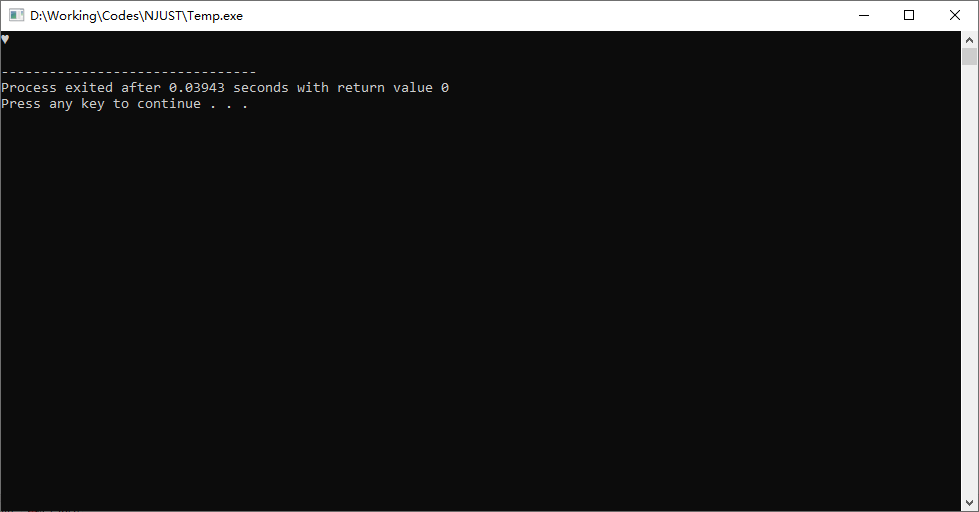
为什么我们得到了一个爱心符号而不是$a+b$的结果$3$呢?
这里要注意我们定义的变量类型。
课上有提到,因为我们的计算的数据和结果数值都很小,用char(可表示-128~127的数)即可存放。但char是字符形,使得最后在输出时输出的数值并非该变量的实际数值,而是对应该ASCII码值的字符,也就是这个爱心。
那这种情况下我们应该怎么让它输出数值呢?让我们看看更改后的代码:
#include <iostream>
using namespace std;
int main()
{
char a, b, c;
a = 1;
b = 2;
c = a + b;
cout << (int)c << endl;
return 0;
}
这里我们将cout语句中的”c”改成了”(int)c”,即将c强制转化为int形后以整形输出,这样就能得到正确的结果了。
2024-10-11 $A\times B$问题
[题目描述]
给定两个整数$A,B$,按规定的输出格式输出这两个整数的积。
[输入说明]
输入两个整数,保证输入的数据和它们的积均在32位整型范围内。
[输出说明]
用如下格式输出两个整数的积:
(如果输入的$A$是$2$, 输入的$B$是$3$)
2x3=6
[样例输入]
2 3
[样例输出]
2x3=6
有同学在看到题目要求后会打出这样的代码:
#include <iostream>
using namespace std;
int main()
{
int a, b;
cout >> "Please Input Two Integers: ";
cin >> a >> b;
cout >> "The Answer is: " >> a >> 'x' >> b >> '=' >> a * b;
return 0;
}
这样写对用户非常友好,毕竟它提示并引导用户输入了数据,在运行的窗口中我们应该会看到这样的显示:
Please Input Two Integers: 2 3
The Answer is: 2x3=6
对于人工检查来说,这样的输出一目了然,但实际上对我们的程序进行判定的是机器,而机器只会机械地对比我们输出的,和应当给出的输出是否一致。
我们来看看这个程序实际上输出了什么:
Please Input Two Integers: The Answer is: 2x3=6
符合题目要求的输出是:
2x3=6
两者并不一致,所以说对于在线评测系统(Online Judge, 通常简称为OJ)来说,这个程序的输出并不符合要求。
所以,题目要求做什么,我们就只做题目要求的事情,不要自作主张输出题目要求以外的内容,否则将会被判定为错误答案。
那么,符合题目要求的代码应该是什么样的呢?
#include <iostream>
using namespace std;
int main()
{
int a, b;
cin >> a >> b;
cout << a << 'x' << b << '=' << a * b << endl;
return 0;
}
上面列出的是一个简单的例子,让大家了解OJ的工作原理。后续我们的上机考试应该都是使用这种方式进行评测,建议同学们先按照这种方式练习打代码,以防止在后续OJ提交时出现这样明明会做,但无法通过评测的情况。
2024-10-18 分离整数与小数
[题目描述]
给定一个浮点数,输出它的整数部分和小数部分。
[输入说明]
输入一个浮点数。
[输出说明]
分别输出这个浮点数的整数部分和小数部分,用空格分隔。
[样例输入]
-32767.65536
[样例输出]
-32767 -0.65536
本题为作业,不进行完整代码演示。仅对其中比较重要的内容进行说明。
浮点数的存储
对于一个浮点数而言,其在计算机内的存储是以科学计数法的方式进行的,那么如果要判定两个浮点数相等,最好的方式是使用极限的定义,即:
取足够小的值$\epsilon$,当两个浮点数的差值小于$\epsilon$即可认为两个浮点数相等。
输出流的控制
见教材Pg. 509页,其中对cout输出流的格式控制中,当在头文件中加入<iomanip>头文件后,可以通过使用setprecision(int)控制浮点数输出的精度,追加fixed是指setprecision(int)中int的值为小数点后的位数,。
不难理解”iomanip”的意思,其名称是Input Output Manipulation(输入输出控制)
如下为一段示例代码:
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
double a = 32767.65536;
cout << a << endl;
cout << fixed << setprecision(2) << a << endl;
return 0;
}
运行这段代码得到的结果是:
32767.7
32767.66
2024-10-25 100以内的素数之和
[题目要求]
输出100以内的所有素数之和
[输入格式]
无
[输出格式]
输出一行整数,表示100以内所有素数之和
[样例输入]
无
[样例输出]
(正确编写程序后即可输出答案)
这道题的重点在于如何判定一个数是否为素数。
我们知道素数是仅能被1及其本身整除的数,所以我们要对素数进行单独验证。
让我们来看一看这样的代码:
#include <iostream>
using namespace std;
int main()
{
int n_Ans = 0;
for (int i = 2; i <= 100; i++)
{
int n_Flag = 1;
for (int j = 2; j * j <= i; j++)
{
if(!(i % j))
{
n_Flag = 0;
break;
}
}
if(n_Flag)
{
n_Ans += i;
}
}
cout << n_Ans << endl;
return 0;
}
这里有聪明的同学要问了,为什么内层嵌套的循环中,循环的条件为$j \times j \leq i$呢?
如果一个数不是素数,其最大的因子就是其平方根,所以大于其平方根的整数我们并不需要做判定,用这样的方式我们可以减少判定的次数,以达到提升程序运行效率的目的。
我们再来看看老师的例程:
#include <iostream>
using namespace std;
int main()
{
int sum = 0;
for (int i = 2; i <= 100; i++)
{
if (i == 2)
{
sum += i;
continue;
}
for (int j = 2; j <= i; j++)
{
if (i == j)
{
sum += i;
}
if (i % j == 0)
{
break;
}
}
}
cout << sum << endl;
return 0;
}
这样额外增加的判断逻辑不仅没有减小执行代码的时间复杂度,而且还因为复杂的逻辑增加了犯错的可能,对于代码的排错来说是不利的(这是已经修正好后的代码,可以对比一下两份代码的逻辑)。
2024-10-25 求一个数的所有质因子
[题目要求]
输入一个正整数$A$,保证$A\leq 2000$,求出这个数的所有质因子,并将其质因子从小到大输出。
[输入格式]
一个整数$A$
[输出格式]
从小到大输出$A$的质因子,以空格隔开
[样例输入]
6
[样例输出]
2 3
判定素数的方式与上一道题相同,注意求其因子和求其是否为质因子的区别。
#include <iostream>
using namespace std;
int main()
{
int n_Num;
cin >> n_Num;
for (int i = 2; i <= n_Num; i++)
{
if (!(n_Num % i))
{
int n_Flag = 1;
for (int j = 2; j * j <= i; j++)
{
if (!(i % j))
{
n_Flag = 0;
break;
}
}
if (n_Flag)
{
cout << i << " ";
}
}
}
cout << endl;
return 0;
}
2024-10-30 函数编写
[题目要求]
写出4个函数,分别求传入的两个整数、传入的三个整数、传入的四个整数的和,以及求从第一个整数到第二个整数之间所有数字之和。
根据题目要求,我们不难写出这样的代码(因未对主函数中的输入和输出进行说明,我们只实现要求编写的函数,并在主函数中调用对应的函数,输出所需要输出的值)。
#include <iostream>
using namespace std;
int n_Sum(int n_NumA, int n_NumB);
int n_Sum(int n_NumA, int n_NumB, int n_NumC);
int n_Sum(int n_NumA, int n_NumB, int n_NumC, int n_NumD);
int n_SumSeg(int n_Left, int n_Right);
int main()
{
cout << n_Sum(1, 2) << endl << n_Sum(1, 2, 3) << endl <<
n_Sum(1, 2, 3, 4) << endl << n_SumSeg(1, 10) << endl;
return 0;
}
int n_Sum(int n_NumA, int n_NumB)
{
return n_NumA + n_NumB;
}
int n_Sum(int n_NumA, int n_NumB, int n_NumC)
{
return n_NumA + n_NumB + n_NumC;
}
int n_Sum(int n_NumA, int n_NumB, int n_NumC, int n_NumD)
{
return n_NumA + n_NumB + n_NumC + n_NumD;
}
int n_SumSeg(int n_Left, int n_Right)
{
int Sum = 0;
for (int i = n_Left; i <= n_Right; i++)
{
Sum = n_Sum(i, Sum);
}
return Sum;
}
下面是老师的代码实现:
#include <iostream>
using namespace std;
int add1(int a, int b);
int add2(int a, int b, int c);
int add3(int a, int b, int c, int d);
int add4(int m, int n);
int main()
{
cout << add1(2.1, 3);
return 0;
}
int add1(int a, int b)
{
return a + b;
}
int add2(int a, int b, int c)
{
return a + b + c;
// return add1(a, b) + c;
// return add1(add1(a, b), c);
}
int add3(int a, int b, int c, int d)
{
return a + b + c + d;
// return add2(a, b, c) + d;
// return add1(add2(a, b, c), d);
// ...
// There are many ways of invoking previous functions to complete the same task.
}
int add4(int m, int n)
{
int sum = 0;
for (int i = m; i <= n; i++)
{
sum += i;
}
return sum;
}
这段代码中,给add1()传入的参数中有浮点数,但实际我们定义的add1函数的两个参数均为int,那么在执行时会将浮点数2.1强制转换为整数2再进行操作。
而事实上,这些函数执行的操作都是相同的,都是进行几个数的加和,他们其实可以叫同一个名字,也就是我前面写的代码的写法。
但,函数名,函数相同吗?
当然不相同,因为函数只要函数名、传入参数列表中变量类型及个数中有任意一个不同,那就不是同一个函数。
如果函数名,传入参数列表中变量类型及个数完全一样,只有返回类型不同的两个函数是不能在同一份代码中出现的,比如下面这个例子,在编译时就会报错提示代码中有二义性。 int add(int a, int b);
double add(int a, int b);
// ^ This is Ambiguous.
在实际执行程序的过程中,根据需要,在主函数中写对应需要的函数的参数,即可以正确进行调用。
所以我们对上面的代码稍作改动,即可正确进行刚才传入浮点数的计算。
#include <iostream>
using namespace std;
int add(int a, int b);
double add(double a, int b); // <- Here, A New Function For Double a and Int b.
int add(int a, int b, int c);
int add(int a, int b, int c, int d);
int add4(int m, int n);
int main()
{
cout << add(2.1, 3);
return 0;
}
int add(int a, int b)
{
return a + b;
}
double add(double a, int b) // <- Here, A New Definition for Double A and Int B
{
return a + (double)b;
}
int add(int a, int b, int c)
{
return a + b + c;
// return add1(a, b) + c;
// return add1(add1(a, b), c);
}
int add(int a, int b, int c, int d)
{
return a + b + c + d;
// return add2(a, b, c) + d;
// return add1(add2(a, b, c), d);
// ...
// There are many ways of invoking previous functions to complete the same task.
}
int add4(int m, int n)
{
int sum = 0;
for (int i = m; i <= n; i++)
{
sum += i;
}
return sum;
}
2024-11-13 质因数分解
[题目描述]
输入一个正整数$n$,从小到大输出$n$的所有质因数。
[输入描述]
一个正整数$n$
[输出描述]
以空格分隔开,以$n=x_1x_2\cdots*x_n$的格式输出该整数的所有质因数
[样例输入]
12
[样例输出]
12=2*2*3
这道题目在习题课上讲过,注意我们之前所写的void FacPrimely(int n)函数的具体实现。
#include <iostream>
using namespace std;
void FacPrimely(int n);
int main()
{
int n;
cin >> n;
cout << "n=";
FacPrimely(n);
return 0;
}
void FacPrimely(int n)
{
if (n == 1)
{
return;
}
if (!(n % 2))
{
while (!(n % 2))
{
n /= 2;
cout << 2;
if (n != 2)
{
cout << '*';
}
}
FacPrimely(n);
return;
}
for (int i = 3; i <= n / i; i += 2)
{
if (!(n % i))
{
cout << i << '*';
FacPrimely(n / i);
return;
}
}
cout << n;
return;
}
2024-11-13 进制转换
[题目描述]
输入一个十进制正整数$n$,分别输出其二进制、八进制和十六进制的表示
[输入格式]
一个十进制正整数$n$
[输出格式]
该十进制整数的二进制、八进制和十六进制,每个表示之间用一个制表符\t隔开
[样例输入]
18
[样例输出]
10010 \22 0x12
这道题目也是之前讲过的内容,通过使用函数进行位运算实现,如果可以的话还可以使用一个函数对它的实现进行简化。
先看未简化的代码。
#include <iostream>
using namespace std;
void v_ToBin(int n_Num);
void v_ToEight(int n_Num);
void v_ToHex(int n_Num);
int main()
{
int n_Num;
cin >> n_Num;
v_ToBin(n_Num);
v_ToEight(n_Num);
v_ToHex(n_Num);
return 0;
}
void v_ToBin(int n_Num)
{
int n_Flag = 0;
int n_Pos = 30;
int n_Check;
while (n_Pos >= 0)
{
n_Check = (n_Num >> n_Pos) & 1;
n_Pos--;
if (n_Check)
{
n_Flag = 1;
}
if (!n_Flag && !n_Check)
{
continue;
}
cout << n_Check;
}
cout << '\t';
return;
}
void v_ToEight(int n_Num)
{
int n_Flag = 0;
int n_Pos = 30;
int n_Check;
cout << '\\';
while (n_Pos >= 0)
{
n_Check = (n_Num >> n_Pos) & 7;
n_Pos -= 3;
if (n_Check)
{
n_Flag = 1;
}
if (!n_Check && !n_Flag)
{
continue;
}
cout << n_Check;
}
cout << '\t';
return;
}
void v_ToHex(int n_Num)
{
int n_Flag = 0;
int n_Pos = 28;
int n_Check;
cout << "0x";
while (n_Pos >= 0)
{
n_Check = (n_Num >> n_Pos) & 15;
n_Pos -= 4;
if (n_Check)
{
n_Flag = 1;
}
if (!n_Check && !n_Flag)
{
continue;
}
if (n_Check >= 10)
{
cout << (char)(n_Check - 10 + 'a');
}
else
{
cout << n_Check;
}
}
cout << '\t';
}
我们发现这样的进制转换其实是同一个轮子反复使用,那其实我们再在参数列表中加一项就可以让代码得到简化。
#include <iostream>
using namespace std;
void Transfer(int n_Num, int n_Type);
int main()
{
int n_Num;
cin >> n_Num;
Transfer(n_Num, 2);
Transfer(n_Num, 8);
Transfer(n_Num, 16);
return 0;
}
void Transfer(int n_Num, int n_Type)
{
int n_Flag = 0;
int n_Pos;
int n_Gap;
int n_Check;
switch(n_Type)
{
case 2:
n_Pos = 30;
n_Gap = 1;
break;
case 8:
n_Pos = 30;
n_Gap = 3;
cout << '\\';
break;
case 16:
n_Pos = 28;
n_Gap = 4;
cout << "0x";
break;
default:
return;
}
while (n_Pos >= 0)
{
n_Check = (n_Num >> n_Pos) & (n_Type - 1);
n_Pos -= n_Gap;
if (n_Check)
{
n_Flag = 1;
}
if (!n_Check && !n_Flag)
{
continue;
}
if (n_Check >= 10)
{
cout << (char)(n_Check - 10 + 'a');
}
else
{
cout << n_Check;
}
}
cout << '\t';
}
2024-11-15 数组统计
[题目描述]
创建一个最大长度为100的数组,对每个元素赋随机值,统计这个数组里的奇数个数,及奇数的平均值。
注:在C++,随机值可以使用<cstdlib>头文件中的rand()函数。一般为了保证随机,还需要使用<ctime>头文件中的time(NULL)作为随机数种子。
下面为一段生成一个随机数并输出的示例代码:
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
int main()
{
srand(time(NULL));
cout << rand() << endl;
return 0;
}
[输入格式]
无
[输出格式]
无特定要求
那么我们可以写出这样的代码。
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
const int SIZE = 100;
int main()
{
int n_Array[SIZE];
double d_Average = 0;
int n_Even = 0;
int n_Odd = 0;
srand(time(NULL));
/* ^ This is to Make Sure that it is REALLY random.
Otherwise, each time you run the program, it will
Output the EXACT SAME RESULT. */
for (int i = 0; i < SIZE; i++)
{
n_Array[i] = rand();
cout << "Element #" << i << ": " << n_Array[i] << endl;
if(n_Array[i] % 2)
{
n_Odd++;
d_Average += (double)n_Array[i];
}
else
{
n_Even++;
}
}
cout << "Total Odd Number: " << n_Odd << endl;
cout << "Total Even Number: " << n_Even << endl;
cout << "Average Of All Odd Number: " << d_Average / (double)n_Odd << endl;
return 0;
}
注意留了注释的那一行代码,如果我们不写这一段代码,那么每次运行这段程序的结果都是完全一样的,没有达到随机生成数的目的。
老师的例程如下:
#include <iostream>
#include <cstdlib>
using namespace std;
typedef unsigned int uint_32;
int main()
{
uint_32 a[100] = {0};
for (uint_32 i = 0; i < 100; i++)
{
a[i] = rand();
}
// Show Array
for (uint_32 i = 0; i < 100; i++)
{
cout << a[i] << '\t';
}
cout << endl;
uint_32 Cnt = 0;
uint_32 Sum = 0;
for (uint_32 i = 0; i < 100; i++)
{
if (a[i] % 2)
{
Cnt++;
Sum += a[i];
}
}
cout << count << endl;
cout << (double)Sum / (double)Cnt << endl;
return 0;
}
如果我们需要限定随机数的范围在0~100之间,只需要让rand()对101取模即可,增加宏定义#define ARRAY_LEN 100后的代码如下。
#include <iostream>
#include <cstdlib>
#define ARRAY_LEN 100
using namespace std;
typedef unsigned int uint_32;
int main()
{
uint_32 a[ARRAY_LEN] = {0};
for (uint_32 i = 0; i < ARRAY_LEN; i++)
{
a[i] = rand() % 101;
}
// Show Array
for (uint_32 i = 0; i < ARRAY_LEN; i++)
{
cout << a[i] << '\t';
}
cout << endl;
uint_32 Cnt = 0;
uint_32 Sum = 0;
for (uint_32 i = 0; i < ARRAY_LEN; i++)
{
if (a[i] % 2)
{
Cnt++;
Sum += a[i];
}
}
cout << count << endl;
cout << (double)Sum / (double)Cnt << endl;
return 0;
}
2024-11-27 上机测验(1) 角谷猜想
[题目描述]
你听说过角谷猜想吗?
任意的正整数,比如5, 我们从它开始,如下规则计算: 如果是偶数,则除以2,如果是奇数,则乘以3再加1。如此循环,最终必会得到“1”! 比如5的处理过程是:5 16 8 4 2 1
一个正整数经过多少步才能变成1, 称为角谷步数。对于5而言,步数也是5;对于1,步数为0。
[输入格式]
输入一个整数n(1<n<300)。
[输出格式]
输出n的角谷步数
[样例输入1]
3
[样例输出1]
7
[样例输入2]
7
[样例输出2]
16
思路: 使用while循环,对输入的数执行角谷猜想的操作,每完成一次操作就更新一次步数,直到数值为1结束。
#include <cstdio>
int n_Num;
int n_Step;
int main()
{
scanf("%d", &n_Num);
while (n_Num != 1)
{
if (n_Num % 2)
{
n_Num = n_Num * 3 + 1;
}
else
{
n_Num /= 2;
}
n_Step++;
}
printf("%d\n", n_Step);
return 0;
}
说明: 这里我根据自己的代码编写习惯使用的是C风格的输入输出方式。
scanf("%d", &n_Num);语句等价于C++中的cin >> n_Num;printf("%d\n", n_Step);语句等价于C++中的cout << n_Step << endl;
2024-11-27 上机测验(2) 分数化简
[题目描述]
将一个分数化简。比如2/4可化简为1/2。
[输入格式]
输入两个整数n,m, 分别表示分子和分母。其中分子n可以是任意整数,分母m不为0。 注意,分子为0时,分母应简化为1。
[输出格式]
输出化简后的分数。
[样例输入1]
-4 6
[样例输出1]
-2/3
[样例输入2]
4 6
[样例输出2]
2/3
[样例输入3]
4 -6
[样例输出3]
-2/3
[样例输入4]
-4 -6
[样例输出4]
2/3
[样例输入5]
0 6
[样例输出5]
0/1
[样例输入6]
-3446459 -6787
[样例输出6]
3446459/6787
思路: 对于输入的两个数,首先我们要对分子的值进行特判,如果分子为0,则直接将分母置为1。
对于分子不为零的情况,我们需要先考虑其正负问题,如果分子为正而分母为负,需要将两者的正负进行对调,如果分子分母均为负,则都应该将其改为正值。
完成了对分子分母的值的初始处理后,接下来我们要做的就是进行约分操作,这里介绍<algorithm>头文件中的__gcd(int a, int b)函数,这个函数会返回两个数的最大公约数。我们求出分子和分母绝对值(可以通过<cmath>头文件中的abs()函数求得,注意类型的转换)的最大公约数之后,让分子分母同时除以这个最大公约数即可得到约简后的分数。
#include <cstdio>
#include <algorithm>
#include <cmath>
using namespace std;
int n_Upper;
int n_Lower;
int n_GCD;
int main()
{
scanf("%d %d", &n_Upper, &n_Lower);
if (!n_Upper)
{
n_Lower = 1;
}
else
{
if ((n_Upper < 0 && n_Lower < 0) || (n_Upper > 0 && n_Lower < 0) )
{
n_Upper = -n_Upper;
n_Lower = -n_Lower;
}
n_GCD = __gcd((int)(abs(n_Upper)), (int)(abs(n_Lower)));
n_Upper /= n_GCD;
n_Lower /= n_GCD;
}
printf("%d/%d\n", n_Upper, n_Lower);
return 0;
}
2024-11-27 上机测验(3) 狭义相同字符对和广义相同字符对
[题目描述]
“狭义相同字符对”是指完全相同的两个字符;“广义相同字符对”是指一个字符串忽略大小写以后相同的两个字符,例如:‘A’和‘a’。先输入一个字符串 (字符长度<1000),计算其中有多少“狭义相同字符对”和“广义相同字符对”。
[输入格式]
输入一组字符串(字符长度<1000),字符串中字符仅限于26个英文字母的大小写字符。
[输出格式]
两个整数,分别为字符串中的“狭义相同字符对”和“广义相同字符对”个数,之间用一个空格分隔开来。注意,字符“aaa”中的相同字符对为3个,分别是第一个a和第二个a,第一个a和第三个a,第二个a和 第三个a。
[样例输入]
abcaAb
[样例输出]
2 4
思路: 对于字符串中的每个字符,均从该字符起向后寻找与之相同(或与之仅有大小写差异)的字符,每找到一个就递增答案。
由于输入保证只包含英文字母,我们可以计算找到的两个字符间的ASCII码值差异的绝对值是否与a和A的ASCII码值差异相同即可,参考代码如下:
#include <cstdio>
#include <cstring>
inline int ABS(int n){ return n < 0 ? (-n): n;}
const int SIZE = 1001;
char s_Str[SIZE];
int n_Length;
int n_Ans1;
int n_Ans2;
int main()
{
scanf("%s", s_Str);
n_Length = strlen(s_Str);
for (int i = 0; i < n_Length; i++)
{
for (int j = i + 1; j < n_Length; j++)
{
if (s_Str[i] == s_Str[j])
{
n_Ans1++;
n_Ans2++;
}
if (ABS(s_Str[i] - s_Str[j]) == ABS('a' - 'A'))
{
n_Ans2++;
}
}
}
printf("%d %d\n", n_Ans1, n_Ans2);
return 0;
}
2024-11-27 上机测验(4) N进制数转换
[题目描述]
N 进制数指的是逢 N进一的计数制。例如,人们日常生活中大多使用十进制计数,而计算机底层则一般使用二进制。除此之外,八进制和十六进制在一些场合也是常用的计数制(十六进制中,一般使用字母 A 至 F 表示十至十五;本题中,十一进制到十五进制也是类似的)。
在本题中,我们将给出n个不同进制的数。你需要分别把它们转换成十进制数。
[输入格式]
输入的第一行为一个十进制表示的整数 N。接下来 N 行,每行一个整数 K,随后是一个空格,紧接着是一个 K进制数,表示需要转换的数。保证所有 K进制数均由数字和大写字母组成,且不以 0开头。保证 K进制数合法。
保证 N≤1000;保证 2≤K≤16。
保证所有 K进制数的位数不超过 9。
[输出格式]
输出 N行,每一个十进制数,表示对应 K进制数的十进制数值。
[样例输入1]
2
8 1362
16 3F0
[样例输出1]
754
1008
[样例输入2]
2
2 11011
10 123456789
[样例输出2]
27
123456789
思路: 用字符串读入数据,随后按规则进行数值转换到一个数组中,再根据进制规则拼出该数据所对应的十进制的数值。
注意:由于输入的字符串长度最大为9,如果输入的十六进制数为FFFFFFFFF,其转换得到的值为68719476735,它已经超出了32位整型表示的数值上限2147483647,应使用long long作为答案的数据类型。
#include <cstdio>
#include <cstring>
const int SIZE = 101;
int n_TotCase;
int n_Length;
int n_K;
long long n_Ans;
char s_Str[SIZE];
int n_Num[SIZE];
int main()
{
scanf("%d", &n_TotCase);
while (n_TotCase--)
{
scanf("%d", &n_K);
scanf("%s", s_Str);
n_Length = strlen(s_Str);
for (int i = 0; i < n_Length; i++)
{
if (s_Str[i] >= '0' && s_Str[i] <= '9')
{
n_Num[i] = s_Str[i] - '0';
}
if (s_Str[i] >= 'A' && s_Str[i] <= 'F')
{
n_Num[i] = 10 + (s_Str[i] - 'A');
}
if (s_Str[i] >= 'a' && s_Str[i] <= 'f')
{
n_Num[i] = 10 + (s_Str[i] - 'a');
}
}
n_Ans = 0;
for (int i = 0; i < n_Length; i++)
{
n_Ans *= (long long)n_K;
n_Ans += (long long)n_Num[i];
}
printf("%lld\n", n_Ans);
}
return 0;
}
2024-11-27 上机测验(5) 寻找目标字符串
[题目描述]
给出一个字符串和多行文字,在这些文字中找到字符串出现的那些行。你的程序还需支持大小写敏感选项:当选项打开时,表示同一个字母的大写和小写看作不同的字符;当选项关闭时,表示同一个字母的大写和小写看作相同的字符。
[输入格式]
输入的第一行包含一个字符串S,由大小写英文字母组成。第二行包含一个数字,表示大小写敏感的选项,当数字为0时表示大小写不敏感,当数字为1时表示大小写敏感。第三行包含一个整数n,表示给出的文字的行数。 接下来n行,每行包含一个字符串,字符串由大小写英文字母组成,不含空格和其他字符。
(1<=n<=100,每个字符串的长度不超过100。)
[输出格式]
输出多行,每行包含一个字符串,按出现的顺序依次给出那些包含了字符串S的行。
[样例输入1]
Hello
1
5
HelloWorld
HiHiHelloHiHi
GrepIsAGreatTool
HELLO
HELLOisNOTHello
[样例输出1]
HelloWorld
HiHiHelloHiHi
HELLOisNOTHello
[样例输入2]
Hello
0
5
HelloWorld
HiHiHelloHiHi
GrepIsAGreatTool
HELLO
HELLOisNOTHello
[样例输出2]
HelloWorld
HiHiHelloHiHi
HELLO
HELLOisNOTHello
思路: 2024-11-27 上机测验(2)题目的升级版,思路类似,只不过从找单一字母变成了找一整个字符串,并且只要找到第一个符合条件的字符串,那就说明这个字符串是符合题目要求的。
#include <cstdio>
#include <cstring>
const int SIZE = 101;
int n_FoundFlag;
int n_UpperSensitive;
int n_StdLength;
int n_CheckLength;
int n_TotCase;
char s_StdStr[SIZE];
char s_CheckStr[SIZE];
inline int ABS(int n) {return n < 0 ? -n : n;}
int main()
{
scanf("%s", s_StdStr);
scanf("%d", &n_UpperSensitive);
scanf("%d", &n_TotCase);
n_StdLength = strlen(s_StdStr);
while (n_TotCase--)
{
n_FoundFlag = 0;
scanf("%s", s_CheckStr);
n_CheckLength = strlen(s_CheckStr);
for (int i = 0; i < n_CheckLength - n_StdLength + 1; i++)
{
n_FoundFlag = 1;
for (int j = 0; j < n_StdLength; j++)
{
if (n_UpperSensitive)
{
if (s_StdStr[j] != s_CheckStr[i + j])
{
n_FoundFlag = 0;
break;
}
}
else
{
if (ABS(s_StdStr[j] - s_CheckStr[i + j]) != ABS('a' - 'A') &&
s_StdStr[j] != s_CheckStr[i + j])
{
n_FoundFlag = 0;
break;
}
}
}
if (n_FoundFlag)
{
break;
}
}
if (n_FoundFlag)
{
printf("%s\n", s_CheckStr);
}
}
return 0;
}
2024-12-04 上机测验(1) 求和问题
[题目描述]
给定两个数$a, n$, 其中$1\leq a \leq 9, 1 \leq n \leq 18$,求$a + aa + aaa + \cdots + a\dots a(一共n个a)$
[输入格式]
两个整数$a, n$,中间用一个空格隔开
[输出格式]
一个整数,该表达式的和
[样例输入]
2 5
[样例输出]
24690
思路: 由于本题数据范围不会超过long long的最大表示范围,可以用long long存储中间变量,随后进行加和得到答案,也可以通过高精度加法模拟手算的过程。
先看手算的过程,即先算出每一位的值,再逐位向前进位:
#include <cstdio>
const int SIZE = 30;
int n_Data[SIZE];
int n_Input;
int n_Length;
int main()
{
scanf("%d %d", &n_Input, &n_Length);
for (int i = 1; i <= n_Length; i++)
{
n_Data[i] = n_Input * (n_Length + 1 - i);
}
for (int i = 1; i <= n_Length; i++)
{
if (n_Data[i] / 10)
{
n_Data[i + 1] += n_Data[i] / 10;
n_Data[i] %= 10;
}
}
while (n_Data[n_Length + 1] / 10)
{
n_Data[n_Length + 1] += n_Data[n_Length] / 10;
n_Data[n_Length] %= 10;
n_Length++;
}
if (n_Data[n_Length + 1])
{
n_Length++;
}
for (int i = n_Length; i >= 1; i--)
{
printf("%d", n_Data[i]);
}
return 0;
}
答案的做法是直接用long long存储中间变量和答案。
#include <iostream>
using namespace std;
int main()
{
long long a, n, temp, ans;
tmep = 0;
ans = 0;
cin >> a >> n;
for (int i = 1; i <= n; i++)
{
temp = 0;
for (int j = 1; j <= i; j++)
{
temp *= 10;
temp += a;
}
ans += temp;
}
cout << ans;
return 0;
}
2024-12-04 上机测验(2) 井底之蛙
[题目描述]
有一只在井底的青蛙,井的高度为$Height(0\leq Height\leq 1000)$,这只青蛙每天能向上跳$Up(0 \leq Up \leq 1000)$,如果当天未能到达井口,则晚上会向下滑$Down(0\leq Down < Up)$,问青蛙多少天能从井中跳出?
[输入格式]
一行,三个整数$Height, Up, Down$,每个整数之间用空格分隔
[输出格式]
一个整数,这只青蛙从井口跳出需要的天数。
[样例输入1]
4 3 1
[样例输出1]
2
[样例输入2]
4 5 3
[样例输出2]
1
思路: 使用while循环,每次向上跳一次,天数+1,并判断是否出井,未出井则下滑,继续循环。
#include <cstdio>
int n_Height;
int n_Cur;
int n_Ans;
int n_Up;
int n_Down;
int main()
{
scanf("%d %d %d", &n_Height, &n_Up, &n_Down);
while (n_Cur < n_Height)
{
n_Cur += n_Up;
n_Ans++;
if(n_Cur >= n_Height)
{
break;
}
n_Cur -= n_Down;
}
printf("%d", n_Ans);
return 0;
}
2024-12-04 上机测验(3) 三角数
[题目描述]
三角数是这样的一串数:$1, 3, 6, 10, 15, 21, 28, 36, 45,\cdots$,给定一个数$n$,求不小于$n$的最小的三角数。
[输入格式]
一个整数$n$
[输出格式]
一个整数,不小于$n$的最小的三角数
[样例输入]
8
[样例输出]
10
思路: 通过循环遍历是否有符合条件的三角数,如有,则输出。
#include <cstdio>
int n_Ans;
int n_Cur;
int n_Input;
int main()
{
scanf("%d", &n_Input);
while (n_Ans < n_Input)
{
n_Ans += n_Cur;
n_Cur++;
}
printf("%d", n_Ans);
return 0;
}
2024-12-04 上机测验(4) 菱形
[题目描述]
给定一个数$n$,输出边长为$n$的菱形,如样例所示,行末不要有多余空格。
[输入格式]
一个数$n(1\leq n\leq 50)$
[输出格式]
边长为$n$的菱形
[样例输入]
6
[样例输出]
*
***
*****
*******
*********
***********
*********
*******
*****
***
*
思路: 使用循环,按照要求输出即可。
#include <cstdio>
int n_TotLine;
int main()
{
scanf("%d", &n_TotLine);
for (int i = 1; i <= n_TotLine; i++)
{
for (int j = 1; j <= n_TotLine - i; j++)
{
printf(" ");
}
for (int j = 1; j <= 2 * i - 1; j++)
{
printf("*");
}
printf("\n");
}
for (int i = n_TotLine - 1; i >= 1; i--)
{
for (int j = 1; j <= n_TotLine - i; j++)
{
printf(" ");
}
for (int j = 1; j <= 2 * i - 1; j++)
{
printf("*");
}
if (i != 1)
{
printf("\n");
}
}
return 0;
}
2024-12-04 上机测验(5) 孪生素数
[题目描述]
当两个素数相差为$2$时,我们可将这两个素数视作孪生素数,例如$(3, 5),(5, 7), (11,13)$。给定一个数$n$,找出不小于$n$的最小孪生素数对。
[输入格式]
一个数$n$
[输出格式]
两个整数,中间用一空格隔开
[样例输入]
8
[样例输出]
11 13
思路: 从输入的数开始向后找,如果找到的数和比它大2的数均为素数,则直接输出。
#include <cstdio>
int n_Num;
bool is_Prime(int n_Check);
int main()
{
scanf("%d", &n_Num);
while (1)
{
if (is_Prime(n_Num) && is_Prime(n_Num + 2))
{
printf("%d %d", n_Num, n_Num + 2);
break;
}
n_Num++;
}
return 0;
}
bool is_Prime(int n_Check)
{
if (n_Check == 1)
{
return false;
}
if (n_Check == 2)
{
return true;
}
if (!(n_Check % 2))
{
return false;
}
for (int i = 3; i <= n_Check / i; i++)
{
if (!(n_Check % i))
{
return false;
}
}
return true;
}
2024-12-06 上机测验(1) 打印空心菱形
[题目描述]
华老师给了你们一个打印任务,让你们打印边长为n的空心菱形。
[输入格式]
输入一行一个整数n(1<=n<=50)。
[输出格式]
打印边长为N的空心菱形(空心菱形的打印形式见样例),每行均以’*‘结尾,每行的’*’之前如果需要用空格补齐对齐,’*’之后不要有多余的空格。
[样例输入]
6
[样例输出]
*
* *
* *
* *
* *
* *
* *
* *
* *
* *
*
思路: 根据题目要求进行输出即可,使用循环。
#include <cstdio>
int n_TotLine;
int main()
{
scanf("%d", &n_TotLine);
for (int i = 1; i <= n_TotLine; i++)
{
for (int j = 1; j < n_TotLine + 1 - i; j++)
{
printf(" ");
}
for (int j = 1; j <= i * 2 - 1; j++)
{
if (j == 1 || j == i * 2 - 1)
{
printf("*");
}
else
{
printf(" ");
}
}
printf("\n");
}
for (int i = n_TotLine - 1; i >= 1; i--)
{
for (int j = 1; j < n_TotLine + 1 - i; j++)
{
printf(" ");
}
for (int j = 1; j <= i * 2 - 1; j++)
{
if (j == 1 || j == i * 2 - 1)
{
printf("*");
}
else
{
printf(" ");
}
}
printf("\n");
}
return 0;
}
平台上的题解代码如下:
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int n,absi;
cin >> n;
for(int i= -n + 1; i < n; i++)
{
absi = i > 0 ? i : -i;
cout << setw(absi + 1) << '*';
if(absi < n-1)
cout << setw(2 * n - 2 * absi - 2) << '*';
cout << endl;
}
return 0;
}
2024-12-06 上机测验(2) 相差1的整数对
[题目描述]
先输入一个正整数n(2到100之间),再输入n个整数(可重复),计算其中有多少对的整数之间相差1。
[输入格式]
先输入要处理的整数的个数n(2<=n<=100),再输入n个整数,并用空格分开。每个整数大小<=1e5
[输出格式]
一个整数,表示n个整数中有多少对的整数相差1。
[样例输入]
5
4 6 7 2 5
[样例输出]
3
[提示]
采用整数数组
思路: 使用<algorithm>库中的sort函数对数组进行排序,对于已经从小到大排好的数组,每一个数组元素向后找比它大1的元素,找到就让答案+1,找完后输出答案。
#include <cstdio>
#include <algorithm>
using namespace std;
const int SIZE = 101;
int n_TotNum;
int n_Data[SIZE];
int n_Ans;
int main()
{
scanf("%d", &n_TotNum);
for (int i = 0; i < n_TotNum; i++)
{
scanf("%d", &n_Data[i]);
}
sort(n_Data, n_Data + n_TotNum);
for (int i = 0; i < n_TotNum; i++)
{
for (int j = i + 1; j < n_TotNum; j++)
{
if (n_Data[j] - n_Data[i] == 1)
{
n_Ans++;
continue;
}
}
}
printf("%d", n_Ans);
return 0;
}
平台上的题解代码如下:
#include <iostream>
using namespace std;
int main()
{
int n,i,a[100],count=0;
cin >> n;
for(i = 1;i <= n; i++) cin >> a[i];
for(i = 1;i <= n; i++)
for(int j = i + 1;j <= n; j++)
if(a[i] - a[j] == 1 || a[i] - a[j] == -1)
count++;
cout<<count;
return 0;
}
2024-12-06 上机测验(3) 矩阵乘法
[题目描述]
小华在学习矩阵相乘,现在老师给了小华一个M*N的矩阵A和一个N*M的矩阵B,让小华计算出这两个矩阵相乘后的结果.
[输入格式]
第一行输入一个整数M和一个整数N.表示矩阵A的大小. 接下来M行,每行有N个整数.第i行第j列的数字表示了矩阵A的第i行第j列的数字. 在接下来N行,每行M个数字,每个数字范围是[0,100000],表示了矩阵B. (1 <= N <= 5,1 <= M <= 5)
[输出格式]
首先输出提示信息A*B,再输出A*B的结果矩阵,输出格式如下: 矩阵的每行占一行,整数之间都有一个空格,记住,每行最后一个整数后面没有空格.最后输出提示信息B*A后输出B*A的结果矩阵,输出格式同上。
[样例输入]
3 4
1 2 3 4
2 2 3 1
5 4 2 3
6 3 2
2 8 1
6 9 5
2 4 6
[样例输出]
A*B
36 62 43
36 53 27
56 77 42
B*A
22 26 31 33
23 24 32 19
49 50 55 48
40 36 30 30
思路:首先需要了解矩阵乘法的意义。
$(AB){ij} = \sum{k = 1}^{n}a_{ik}b_{kj}=a_{i1}b_{1j} + a_{i2}b_{2j}+\cdots+a_{in}b_{nj}$
注意题目给出的数据范围,在极限数据情况下,即两个$5\times5$的值均为$100000$的矩阵相乘,其结果的数值会超出int的表示范围,应使用long long存储矩阵的数据及答案。
#include <cstdio>
const int SIZE = 6;
long long n_A;
long long n_B;
long long n_Matrix1[SIZE][SIZE];
long long n_Matrix2[SIZE][SIZE];
long long n_Result1[SIZE][SIZE];
long long n_Result2[SIZE][SIZE];
int main()
{
scanf("%lld %lld", &n_A, &n_B);
for (int i = 1; i <= n_A; i++)
{
for (int j = 1; j <= n_B; j++)
{
scanf("%lld", &n_Matrix1[i][j]);
}
}
for (int i = 1; i <= n_B; i++)
{
for (int j = 1; j <= n_A; j++)
{
scanf("%lld", &n_Matrix2[i][j]);
}
}
printf("A*B\n");
for (int i = 1; i <= n_A; i++)
{
for (int j = 1; j <= n_A; j++)
{
for (int m = 1; m <= n_B; m++)
{
n_Result1[i][j] += n_Matrix1[i][m] * n_Matrix2[m][j];
}
printf("%lld", n_Result1[i][j]);
if (j != n_A)
{
printf(" ");
}
}
printf("\n");
}
printf("B*A\n");
for (int i = 1; i <= n_B; i++)
{
for (int j = 1; j <= n_B; j++)
{
for (int m = 1; m <= n_A; m++)
{
n_Result2[i][j] += n_Matrix1[m][j] * n_Matrix2[i][m];
}
printf("%lld", n_Result2[i][j]);
if (j != n_B)
{
printf(" ");
}
}
printf("\n");
}
return 0;
}
平台上的题解代码如下:
#include <iostream>
using namespace std;
int main()
{
long long a[6][6], b[6][6];
int m, n, x, y;
cin >> m >> n;
y = m;
x = n;
for(int i = 0; i < m; i++)
{
for(int j = 0; j < n; j++)
cin >> a[i][j];
}
for(int i = 0; i < x; i++)
{
for(int j = 0; j < y; j++)
cin >> b[i][j];
}
cout << "A*B" << endl;
for(int i = 0; i < m; i++)
{
for(int j = 0; j < y; j++)
{
long long sum=0;
for(int k = 0; k < n; k++)
{
sum+=a[i][k]*b[k][j];
}
cout<<sum<<" ";
}
cout<<endl;
}
cout<<"B*A"<<endl;
for(int i = 0; i < x; i++)
{
for(int j = 0; j < n; j++)
{
long long sum = 0;
for(int k = 0; k < y; k++)
{
sum+=b[i][k]*a[k][j];
}
cout << sum << " ";
}
cout<<endl;
}
return 0;
}
2024-12-06 上机测验(4) 逐单词逆序输出字符串
[题目描述]
输入一句英文,请你反转这句英文中每个单词的字符顺序,但保留空格和单词的顺序,这句英文长度不超过1000,前后可能有空格,其中的单词可能由多个空格分隔。
[输入格式]
输入一条英文句子,即一个字符串。该字符串前后可能有空格,字符串中的空格也可能连续,字符串的长度不超过1000。
[输出格式]
输出一条字符串,该字符串将所输入的字符串中每个单词反转字符顺序,但保留空格和单词的顺序。
[样例输入]
I'm in Nanjing University of Science and Technology.
[样例输出]
m'I ni gnijnaN ytisrevinU fo ecneicS dna .ygolonhceT
思路: 如果不考虑单词之间的空格,原则上是可以通过逐个读入单词并逐个逆序输出得到结果。而本题目要求保留开头、结尾和单词之间的全部空格(单词之间可能不只1个空格),所以只能将完整字符串读入后,原封不动输出空格,并对找到的单词逐个进行逆序输出。
#include <cstdio>
#include <iostream>
#include <cstring>
using namespace std;
const int SIZE = 1001;
int n_Length;
int n_StartPos;
int n_EndPos;
char s_Str[SIZE];
int main()
{
cin.getline(s_Str, SIZE);
n_Length = strlen(s_Str);
n_StartPos = 0;
while (n_StartPos < n_Length)
{
while (s_Str[n_StartPos] == ' ')
// Handle Spaces
{
printf(" ");
n_StartPos++;
}
if (!s_Str[n_StartPos])
// Check if Reach the End of String
{
break;
}
n_EndPos = n_StartPos;
// We Find a Word
while (s_Str[n_EndPos] != ' ' && s_Str[n_EndPos])
// Check the End Position of that word
{
n_EndPos++;
}
n_EndPos--;
for (int i = n_EndPos; i >= n_StartPos; i--)
// Output Reversed Word
{
printf("%c", s_Str[i]);
}
n_StartPos = n_EndPos + 1;
// Go on checking the Next Space
}
return 0;
}
平台上的题解代码如下:
(思路类似,不过这份代码是将找到的单词先在字符串中逆序,再在最后统一输出)
#include<iostream>
using namespace std;
int main()
{
string s;
getline(cin, s);
int begin, end;
int n = s.length();
for(int i = 0;i < n;)
{
while(s[i] == ' ' && i < n)
i++;
if(i>=n)
break;
begin = i;
while(s[i] != ' ' && i < n)
i++;
end=i;
for(int k = begin;k<=(begin+end-1)/2;k++)
swap(s[k],s[end+begin-k-1]);
}
cout << s;
return 0;
}
2024-12-06 上机测验(5) 同构数
[题目描述]
同构数是这样一组数:它出现在平方数的右边。例如;5是25右边的数,25是625右边的数,5和25都是同构数。
编写程序,找出1至n之间的全部同构数。
[输入格式]
输入正整数n
[输出格式]
输出n以内的全部同构数(包括n)
每行输出一个数
[样例输入]
50
[样例输出]
1
5
6
25
思路: 对于给定的$n$,从$1$到$n$分别求该数的平方,随后比对该数和其平方的对应末位是否相等,如果相等,则输出答案。
#include <cstdio>
int n_Range;
int n_Flag;
int n_Check;
int n_CheckSum;
int main()
{
scanf("%d", &n_Range);
for (int i = 1; i <= n_Range; i++)
{
n_CheckSum = i * i;
n_Check = i;
n_Flag = 1;
while (n_Check)
{
if (n_Check % 10 == n_CheckSum % 10)
// Check the Number
{
n_Check /= 10;
n_CheckSum /= 10;
continue;
}
n_Flag = 0;
break;
}
if (n_Flag)
{
printf("%d\n", i);
}
}
return 0;
}
平台上的题解代码如下:
(比对数值的方式有些许不同,这份代码的解法是先找到$m$的位数,然后对$m * m$取模,看是否相同)
#include <iostream>
using namespace std;
int main()
{
int m, i, k, j, n;
cin >> n;
for(m = 1; m <= n; m++)
{
i = 1;
k = m;
j = m * m;
while (k != 0)
{
k /= 10;
i *= 10;
}
if(j % i == m)
{
cout<<m<<endl;
}
}
return 0;
}
上课内容总结
本部分是对上课内容的简单总结,可能会有遗漏,欢迎指出。
常用变量类型的占用空间大小、表示范围
| 类型名称 | 关键字 | 内存占用空间 | 表示范围 |
|---|---|---|---|
| 字符形 | char | 1 Byte | $-128$~$127$ |
| 短整形 | short | 2 Byte | $-32768$~$32767$ |
| 整形 | int | 4 Byte | $-2147483648$~$2147483647$ |
| 长整形 | long long | 8 Byte | $-2^{63}$~$(2^{63}-1)$ |
| 无符号字符形 | unsigned char | 1 Byte | $0$~$255$ |
| 无符号短整形 | unsigned short | 2 Byte | $0$~$65535$ |
| 无符号整形 | unsigned int | 4 Byte | $0$~$4294967295$ |
| 无符号长整形 | unsigned long long | 8 Byte | $0$~$(2^{64}-1)$ |
| 布尔形 | bool | 1 Byte | $0$(False), $1$(True) |
在实际编程过程中可根据自己的实际需求选择所需要的变量类型进行存储和运算,并规避可能的溢出问题。
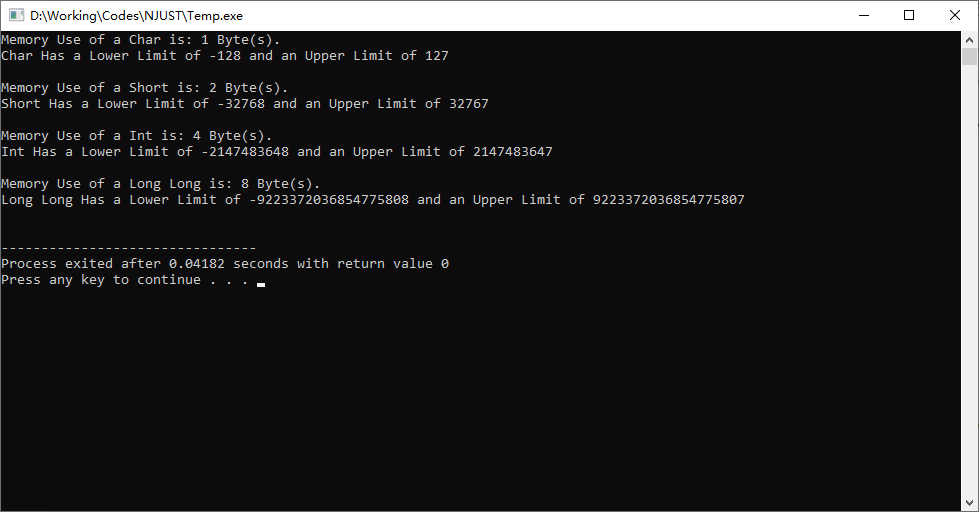
而这些数值上限并不需要我们严格记忆,在<climits>头文件中,我们可以找到这些数值的上下限,以下面的代码作为示例。
#include <iostream>
#include <climits>
using namespace std;
int main()
{
cout << "Memory Use of a Char is: " << sizeof(char) << " Byte(s)." << endl;
cout << "Char Has a Lower Limit of " << CHAR_MIN << " and an Upper Limit of " << CHAR_MAX << endl << endl;
cout << "Memory Use of a Short is: " << sizeof(short) << " Byte(s)." << endl;
cout << "Short Has a Lower Limit of " << SHRT_MIN << " and an Upper Limit of " << SHRT_MAX << endl << endl;
cout << "Memory Use of a Int is: " << sizeof(int) << " Byte(s)." << endl;
cout << "Int Has a Lower Limit of " << INT_MIN << " and an Upper Limit of " << INT_MAX << endl << endl;
cout << "Memory Use of a Long Long is: " << sizeof(long long) << " Byte(s)." << endl;
cout << "Long Long Has a Lower Limit of " << LLONG_MIN << " and an Upper Limit of " << LLONG_MAX << endl << endl;
return 0;
}
这里我们可以看到这些变量的上下限值可以用常量的形式输出出来,同时sizeof(int)可以用来表示变量使用内存的大小(以字节为单位)。
运行得到的结果如下图所示:
变量命名规则
除不能与关键字、保留字重复外,开头只允许使用下划线或字母,并且变量名称(或称标识符)的其他位只能由下划线、字母和数字进行组合,并区分大小写。
算术运算符
| 符号 | 作用 |
|---|---|
| + | 计算两数之和 |
| - | 计算两数之差 |
| * | 计算两数之积 |
| / | 计算两数之商 |
| % | 计算两数之模,即做除法后取余数(例如5%4=1, 因为用4除5余数为1) |
| ^ | 计算乘方(例如$2^{2}$在代码中写作2^2) |
逻辑运算符
| 符号 | 作用 |
|---|---|
| & | 对两个二进制数进行取”与”运算 |
| | | 对两个二进制数进行逐位取”或”运算 |
| ~ | 对数据的二进制补码逐位取反 |
| ! | 若数字不是0,则置为0,若数字是0,则置为1 |
| && | 对两侧条件进行且运算,所得结果为真(1)或假(0) |
| || | 对两侧条件进行或运算,所得结果为真(1)或假(0) |
需要注意的是,C++中,当数值的值不为0,即被视为真,为0则视为假。
位运算符
| 符号 | 作用 |
|---|---|
| « | 将二进制整数左移对应位数(例如0B1100 « 1=0B11000) |
| » | 将二进制整数右移对应位数(例如0B1101 » 1=0B110) |
为了更好地理解这些运算符的作用,我们不妨直接写写代码来直观地看。
#include <iostream>
using namespace std;
int main()
{
int a, b;
// 先进行算术运算符的计算
a = 100;
b = 55;
cout << a + b << endl << a - b << endl;
cout << a * b << endl << a / b << endl;
cout << a % b << endl << endl;
// 再进行逻辑运算符的计算,为直观表现,我们使用二进制的方式
// a = 0B1100100
// b = 0B0110111
cout << (a & b) << endl << (a | b) << endl;
cout << ~a << endl << !a << endl;
cout << (a && b) << endl << (a || b) << endl << endl;
// 位运算
cout << (a << 1) << endl;
cout << (a >> 1) << endl;
return 0;
}
运行这段代码,看看结果。
155
45
5500
1
45
36
119
-101
0
1
1
200
50
想一想位运算的结果, 再和下方的解释进行对比。
0B1100100 & 0B0110111 = 0B0100100 = 36
0B1100100 | 0B0110111 = 0B1110111 = 119
~0B1100100 = ~(0000 0000 0000 0000 0000 0000 0110 0100) = (1111 1111 1111 1111 1111 1111 1001 1011) = -101
[写为完整32位整形后对包括符号位的所有位的数据全部取反,其实际效果等同于将十进制数取负后再-1]
!0B1100100 = 0
[数字不为0,结果为0]
0B1100100 && 0B0110111 = 1
[两个数据都不是0,都表达为真,真且真为真(1)]
0B1100100 || 0B0110111 = 1
[两个数据都不是0,都表达为真,真或真为真(1)]
0B1100100 << 1 = 0B11001000 = 200
0B1100100 >> 1 = 0B110010 = 50
条件运算符
在书写赋值语句时会用到,我们来看以下代码:
#include <iostream>
using namespace std;
int main()
{
int a, b, c;
a = 1;
b = 2;
c = (a > b) ? a : b;
cout << c << endl;
return 0;
}
这里出现了一个比较奇怪的赋值语句。
c = (a > b) ? a : b;
在运行过程中,这个语句的执行逻辑是,判断$a>b$是否为真,如果为真,则将$a$的值赋给$c$,如果为假,则把$b$的值赋给$c$。
那么我们运行这段代码得到的结果是:
2
本质上这段代码的执行逻辑可以等同于下列代码:
if (a > b)
{
c = a;
}
else
{
c = b;
}
上课时的例程代码更有意思,我们来看看:
#include <iostream>
using namespace std;
int main()
{
int a;
cin >> a;
a = (a > 0) ? a : (-a);
cout << a << endl;
return 0;
}
想一想,这样的代码执行效果是什么呢?
赋值运算符
| 符号 | 作用 | 示例 | 备注 |
|---|---|---|---|
| = | 将表达式右侧的值赋给表达式左侧的变量 | a = 2 | |
| += | 将表达式右侧的值加到表达式左侧的变量中 | a += 2 | 等同于a = a + 2,其效果为将a的值增加2 |
| -= | 将表达式右侧的值取负后加到表达式左侧的变量中 | a -= 2 | 等同于a = a - 2,其效果为将a的值减少2 |
| *= | 将表达式右侧的值乘到表达式左侧的变量中 | a *= 3 | 等同于 a = a * 3,其效果为将a的值乘3倍 |
| /= | 用表达式右侧的值除表达式左侧的变量 | a /= 2 | 等同于 a = a / 2,其效果为用2除a |
| %= | 用表达式右侧的值对表达式左侧的变量取模 | a %= 2 | 等同于 a = a % 2,其效果为用2对a取模 |
| &= | 将表达式两侧的值进行按位与运算后赋给左侧变量 | a &= 1 | 等同于 a = a & 1 |
当表达式两侧的变量类型不同时,请务必注意在变量类型发生转换时发生的高位截断,或浮点数转整数损失小数位的问题。
还是以代码进行示例。
#include <iostream>
using namespace std;
int main()
{
unsigned int a = 0x0f123c5b;
unsigned char b;
b = a;
cout << hex << (int)b << endl;
double c = 32767.65536;
int d;
d = c;
cout << dec << d << endl;
return 0;
}
我们知道unsigned int型占用长度是4个字节,而unsigned char型仅占1个字节,那么在进行赋值时,会将unsigned int型舍去前3个字节的值后将剩余的值存入unsigned char型,而浮点数则会读值后仅保留整数赋给d。
那我们运行程序看看输出的结果。
5b
32767
这个时候就有聪明的同学要问了,取整是怎么取的呢,如果浮点数是负数要怎么办呢?
不妨直接改代码看看。
#include <iostream>
using namespace std;
int main()
{
double c = -32767.65536;
int d;
d = c;
cout << d << endl;
return 0;
}
运行结果是:
-32767
所以,以这段代码为例,我们可以知道,对负数的浮点数,将其转换为整型时并非向下取整,而是只保留其整型的部分。
逗号运算符
int a = 10;
int b = 20;
int c = 30;
可以写成这样:
int a = 10, b = 20, c = 30;
注意代码的执行顺序是从左到右执行,所以在书上我们就可以看到这样的坑逼代码(要能看懂,但自己别主动写这样的疑惑代码,否则会被打)
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int b = 20;
int c = a, b + 5;
cout << c << endl;
return 0;
}
运行的结果是:
25
在运行时,CPU先将$a$的值读入缓存中,随后将$b$读入缓存,对其进行$b+5$运算后赋给$c$。
自增自减运算符
在单独成为一个语句时,a++和++a等价,重点是在赋值或判断的过程的先后顺序。
对于a++,这个语句会先将a进行赋值或判断,再对a进行自增操作。
同样以代码示例:
#include <iostream>
using namespace std;
int main()
{
int a = 1;
cout << a++ << endl;
cout << ++a << endl;
return 0;
}
其运行结果是:
1
3
sizeof运算符
丈量变量类型所占内存,其值以字节为单位,在之前的总结中已经有提到过。
typeid运算符
获得变量所属类型。
还是用代码示例:
#include <iostream>
#include <typeinfo>
using namespace std;
int main()
{
int a;
cout << typeid(a).name() << endl;
return 0;
}
其输出结果是:(根据编译器不同有不同输出,如下是Dev Cpp使用GCC输出的值)
i
类型转换
隐式类型转换
(自动完成,当赋值语句两侧类型不同时会将类型转换为相同,随后计算赋值,前文已有提到,此处不再做额外说明,详细内容见书)
显式类型转换
(人工指定类型进行转换,在之前10月09日的上机练习中已经出现过,不再重复说明)
顺序语句
我们之前写的所有代码都是顺序语句,即按顺序执行的语句,此处不多额外说明。
选择语句
if-else语句
可以表示为(下方为伪代码):
if(Condition 1 Met)
{
//Do Something
}
else if(Condition 2 Met) // Condition 1 is False, but Condition 2 is True
{
//Do Something
}
else // Neither Condition 1 nor Condition 2 is True
{
// Do Something
}
用这样的语句形式可以套很多条件,不仅限于两个条件。
示例程序:对学生成绩进行分级。
#include <iostream>
using namespace std;
int main()
{
double score;
cin >> score;
if(score > 100 || score < 0)
{
cout << "Invalid Input" << endl;
}
else if(score >= 90)
{
cout << "Grade: A" << endl;
}
else if(score >= 80)
{
cout << "Grade: B" << endl;
}
else if(score >= 70)
{
cout << "Grade: C" << endl;
}
else if(score >= 60)
{
cout << "Grade: D" << endl;
}
else
{
cout << "Grade: E(Fail)" << endl;
}
return 0;
}
这个时候就有同学要问了,为什么我不在第一个else if语句处判定(score <= 100)呢?
因为代码执行第一个else if语句时,已经执行过if(score > 100 || score < 0)的判断,且这个条件不为真,那么进行 else if(score >=90) 判断时,已经确认score<=100且score>=0,没有必要再将其写入条件。
switch语句
枚举可能出现的值,并依枚举出的值对其进行判断,为了防止出现在执行过程中改变被判断变量的问题,在每个情况下执行完相应操作后都要写break语句。
我们来看一个错误示例。
#include <iostream>
using namespace std;
int main()
{
int score = 100;
switch(score/10)
{
case 10:
case 9:
cout << "A" << endl;
case 8:
cout << "B" << endl;
case 7:
cout << "C" << endl;
case 6:
cout << "D" << endl;
default:
cout << "Fail" << endl;
}
return 0;
}
这段代码输出的结果是:
A
B
C
D
Fail
显然不是我们想要的结果,这就是因为swtich语句中不遇break不会跳出语句块,导致将下面的语句全部执行。
那么修改正确的代码是:
#include <iostream>
using namespace std;
int main()
{
int score = 100;
switch(score/10)
{
case 10:
case 9:
cout << "A" << endl;
break;
case 8:
cout << "B" << endl;
break;
case 7:
cout << "C" << endl;
break;
case 6:
cout << "D" << endl;
break;
default:
cout << "Fail" << endl;
break;
}
return 0;
}
这次的输出是:
A
符合要求。
调试
在Dev Cpp中,如要调试代码,可在代码中打上断点后点击上方的对勾按钮进行调试。
调试过程中可添加查看,以查看变量的值在代码运行过程中的变化情况。
循环语句
对于反复执行的语句,我们可以使用循环语句执行。
for循环
格式如下:
for ([初始条件]; [目标条件]; [递增语句])
//Do Sth
初始条件:即为循环开始的条件;
目标条件:即为循环结束的条件;
递增条件:即为循环进行过程中,每执行一次循环体后执行的操作,通常为使循环变量自增。
示例代码:(输出从1-10的所有数字,每个数字单独一行)
#include <iostream>
using namespace std;
int main()
{
for (int i = 0; i < 10; i++)
{
cout << i + 1 << endl;
}
return 0;
}
运行这段代码得到的结果是:
1
2
3
4
5
6
7
8
9
10
这里需要注意的是,为什么我会选择让$i$从0开始,而不是从1开始呢?
我们知道,计算机内,数字是从0开始递增,而不是从1开始递增,所以对于一个十个元素的数组(之后会遇到)a[10],其数组的下标是a[0], a[1], a[2], a[3], …, a[9].
所以同样是执行十次,让循环变量从0开始执行时,会更符合数组下标的变化情况,从而防止可能出现的数组下标越界导致的程序异常。
还有一个问题,一定要写满三个条件吗?
答案是可以选择性地留空,比如初始条件在循环体外定义,自增操作在循环体内进行等。
但一定要注意不要让循环成为死循环(即不可能结束的无限执行的循环,如果没有在for循环的括号中定义目标条件,那就一定要在循环体中通过条件语句判断并使用break语句跳出循环)。
上课例程:通过for循环的嵌套,输出九九乘法表:
#include <iostream>
using namespace std;
int main()
{
for(int i = 0; i < 9; i++)
{
for (int j = 0; j <= i; j++)
{
cout << (i + 1) << '*' << (j + 1) << '=' << (i + 1) * (j + 1);
if (j != i)
{
cout << '\t';
}
}
cout << endl;
}
return 0;
}
输出结果是
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
while和do-while循环
相比for循环,while循环更加简单,其格式为:
while(条件)
{
// Do Sth
}
当符合条件时,即执行循环体中的语句。注意是先判断,再执行。
另一种是do-while,相比while语句,它是先执行,再判断。
do
{
// Do Sth
}while(条件);
示例程序:
#include <iostream>
using namespace std;
int main()
{
int i = 0;
while(i < 10)
{
cout << (i + 1) << ' ';
i++;
}
do
{
cout << (i + 1) << ' ';
i++;
}while(i < 10);
return 0;
}
输出结果:
1 2 3 4 5 6 7 8 9 10 11
想想为什么最后会输出11.
break和continue
break代表直接终止循环,而continue则跳过后续代码,直接进入下一次循环。
示例代码:
#include <iostream>
using namespace std;
int main()
{
for (int i = 0; i < 10; i++)
{
if (i == 3)
{
continue;
}
cout << (i + 1) << ' ';
}
cout << endl;
for (int i = 0; i < 10; i++)
{
if (i == 3)
{
break;
}
cout << (i + 1) << ' ';
}
return 0;
}
运行结果为:
1 2 3 5 6 7 8 9 10
1 2 3
思考这个运行结果的原因。
函数
由2024年10月25日课前的代码练习引入思考一件事。
既然我在这两份代码里都有判断素数的逻辑,如果我们每次都写这么一大串,太麻烦了,有没有办法让代码简化下来呢?当然有,这就是我们今天引进讲解的内容:函数。
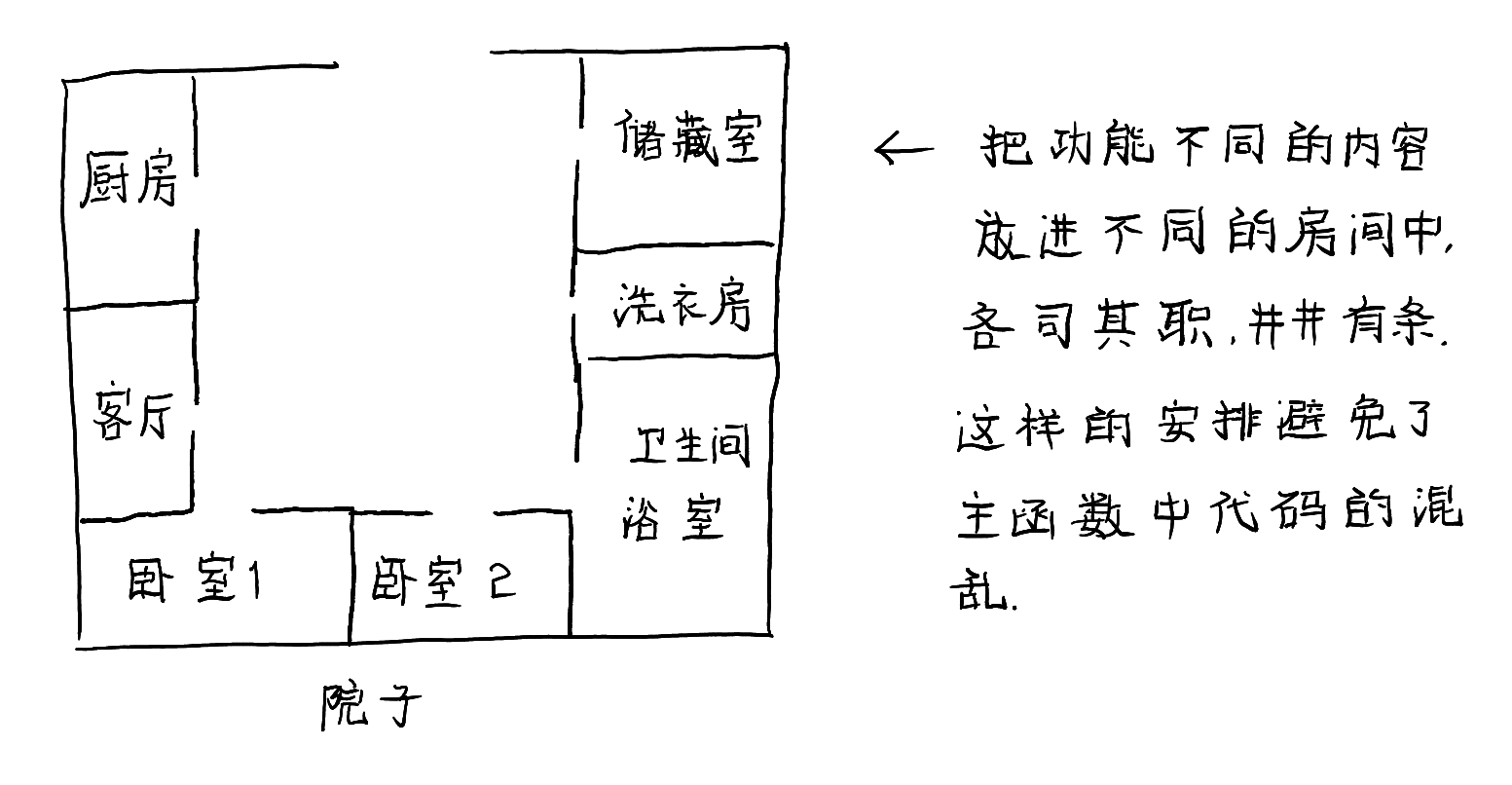
简言之,函数就是我们造的可以重复用的轮子,打包好后,以简化代码中的重复操作,同时也可以。
如果把我们的代码比作一间屋子的话,那么函数的作用就是像这张图一样让它的摆设和运行都井井有条:
函数的格式为:
Return_Type Function_Name(Parameter 1, Parameter 2, ..., Parameter n)
Return_Type: 函数的返回值 Function_Name: 函数的名字 Parameter 1, … n: 函数的参数
函数的声明(Declaration)
我们以两数加和的函数为例。
int add(int a, float b);
声明了该函数,并不代表这个函数就存在。
函数的实现 / 定义(Definition)
我们还是以两数加和的函数为例。
int add(int a, float b)
{
int c = a + b;
return c;
}
函数的调用(Invoke)
在有函数声明和实现的情况下,我们可以在代码中对函数进行调用。
int x = 2;
float y = 20.0;
int sum = add(x, y); // Function is Invoked Here.
应用
既然课前练习的代码中判断素数的代码被反复调用,我们不妨将其封装成一个函数,就像下面这段代码一样。
#include <iostream>
using namespace std;
bool is_Prime(int n_Check); // Function Declaration
int main()
{
int sum = 0;
for (int i = 2; i < 101; i++)
{
if (is_Prime(i))
{
sum += i;
}
}
cout << sum << endl;
return 0;
}
bool is_Prime(int n_Check) // Function Definition
{
if (!(n_Check % 2))
{
if (n_Check == 2)
{
return true;
}
else
{
return false;
}
}
for (int i = 3; i * i <= n_Check; i += 2)
{
if (!(n_Check % i))
{
return false;
}
}
return true;
}
函数的声明和定义是可以同时进行的。
如果在主函数之前声明过函数,可不在主函数之前对函数进行实现,但如果未在主函数之前进行声明,会导致报错,也就是会像下面这样。
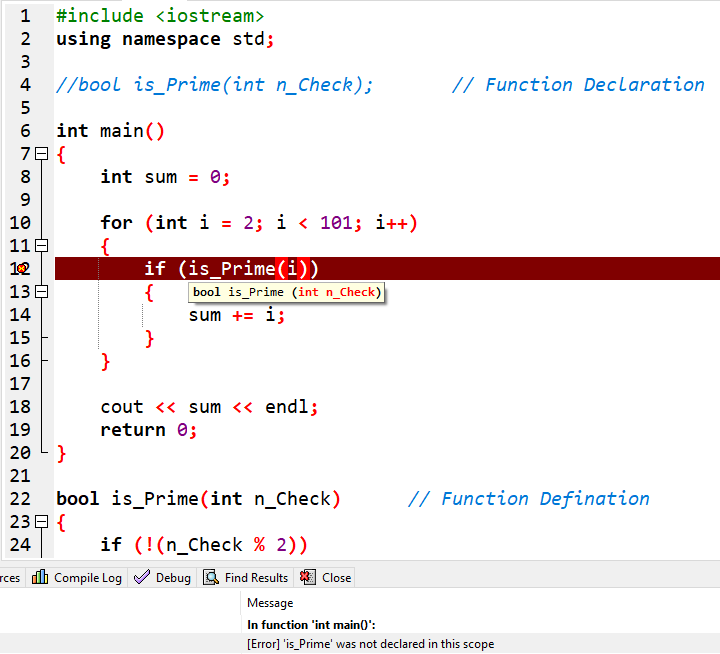
那我们如果再进行封装的话,主函数还能简化到什么地步呢?
#include <iostream>
using namespace std;
bool is_Prime(int n_Check); // Function Declaration
int n_CalcSum(int n_MAX);
int main()
{
cout << n_CalcSum(100) << endl;
return 0;
}
bool is_Prime(int n_Check) // Function Definition
{
if (!(n_Check % 2))
{
if (n_Check == 2)
{
return true;
}
else
{
return false;
}
}
if (n_Check == 1)
{
return false;
}
for (int i = 3; i * i <= n_Check; i += 2)
{
if (!(n_Check % i))
{
return false;
}
}
return true;
}
int n_CalcSum(int n_MAX)
{
int n_Result = 0;
for (int i = 2; i <= n_MAX; i++)
{
n_Result += is_Prime(i) ? i : 0;
}
return n_Result;
}
如果我们想要对输出某一区间内所有质数之和,那可以再造一个更好用的轮子。
#include <iostream>
using namespace std;
bool is_Prime(int n_Check); // Function Declaration
int n_CalcSum(int n_Left, int n_Right);
int main()
{
cout << n_CalcSum(1, 100) << endl;
return 0;
}
bool is_Prime(int n_Check) // Function Definition
{
if (!(n_Check % 2))
{
if (n_Check == 2)
{
return true;
}
else
{
return false;
}
}
if (n_Check == 1)
{
return false;
}
for (int i = 3; i * i <= n_Check; i += 2)
{
if (!(n_Check % i))
{
return false;
}
}
return true;
}
int n_CalcSum(int n_Left, int n_Right)
{
int n_Result = 0;
for (int i = n_Left >= 2 ? n_Left : 2; i <= n_Right; i++)
{
n_Result += is_Prime(i) ? i : 0;
}
return n_Result;
}
同样的,对于课前练习的第二道题而言,用函数实现之后的主函数也非常简单。
#include <iostream>
using namespace std;
bool is_Prime(int n_Check); // Function Declaration
void v_CalcAndOutput(int n_MAX);
int main()
{
int n_Num;
cin >> n_Num;
v_CalcAndOutput(n_Num);
return 0;
}
bool is_Prime(int n_Check) // Function Definition
{
if (!(n_Check % 2))
{
if (n_Check == 2)
{
return true;
}
else
{
return false;
}
}
if (n_Check == 1)
{
return false;
}
for (int i = 3; i * i <= n_Check; i += 2)
{
if (!(n_Check % i))
{
return false;
}
}
return true;
}
void v_CalcAndOutput(int n_MAX)
{
for (int i = 2; i <= n_MAX; i++)
{
if (!(n_MAX % i))
{
if (is_Prime(i))
{
cout << i << " ";
}
}
}
return;
}
函数的重载
函数的重载体现了代码的多态。
C++的特性:多态、封装、继承(派生)
在2024年10月30日课前代码练习中,我们已经提到了这个特性,因为区分函数的方式是看函数名与参数列表中参数的个数和类型不同,所以我们可以写出多个同名,但参数列表不同的函数,以提升代码的可读性。
可变形参
如果我们希望函数后面的参数可以更多,但又不单独对这些函数进行实现呢?
让我们来看看可变形参,以下为其中一种声明。
int add(double a, bool b ,int c, ...);
这里表示一个至少有3个参数的函数,其中,第一参数是双精度整数a,第二参数是布尔型变量b,第三个参数及之后的所有参数都是整数。
可变形参是指数量可变,但类型必须与”…“之前声明的变量类型相同。
上课时的例程如下,用”-1”代表最后一个数:
#include <iostream>
#include <cstdarg> // va_list, va_arg, va_start, va_end is defined in <cstdarg>
using namespace std;
int n_Add(int n_NumA, ...); // In this code, we define that "-1" is the last argument
int main()
{
cout << n_Add(1, 2, 3, 4, 5, 6, 7, 8, 9, -1);
return 0;
}
int n_Add(int n_NumA, ...)
{
int n_Sum = n_NumA;
int n_Read = -1;
va_list savelist; // Define a savelist
va_start(savelist, n_NumA); // Save the Parameters Read After "n_NumA"
while(1)
{
n_Read = va_arg(savelist, int); // Read the First Unread Argument
if(n_Read == -1) // Check if We Read All
{
break;
}
n_Sum += n_Read; // Get it Added to Sum
}
va_end(savelist); // End the Use of savelist and Release Memory
return n_Sum;
}
或者这样写,通过看前面”n_Count”传入的值以限制后续读入的总变量个数。
#include <iostream>
#include <cstdarg> // va_list, va_arg, va_start, va_end is defined in <cstdarg>
using namespace std;
int n_Add(int n_Count, ...);
int main()
{
cout << n_Add(5, 1, 2, 3, 4, 5) << endl;
return 0;
}
int n_Add(int n_Count, ...)
{
int n_Sum = 0;
int n_Read;
va_list savelist; // Define a savelist
va_start(savelist, n_Count); // Save the Parameters Read After "n_Count"
for (int i = 0; i < n_Count; i++)
{
n_Read = va_arg(savelist, int); // Read the First Unread Argument
n_Sum += n_Read;
}
va_end(savelist); // End the use of savelist and Release Memory
return n_Sum;
}
默认形参
在声明函数时,可以指定在不传入该参数时,该参数默认的值,例如:
int add(int a, int b, int param = 1);
则这个函数可以用如下方式调用:
add(200, 300);
add(200, 300, 1);
这两种方式等效,可参见如下例程。
#include <iostream>
using namespace std;
double d_Add(int n_NumA, int n_NumB, int n_Positive = 1, double d_Multiplier = 1.00);
int main()
{
cout << d_Add(200, 300);
return 0;
}
double d_Add(int n_NumA, int n_NumB, int n_Positive, double d_Multiplier)
{
return d_Multiplier * (double)(n_Positive * (n_NumA + n_NumB));
}
double d_Add(int n_NumA, int n_NumB, int n_Positive = 1, double d_Multiplier);
对于同名函数,注意避免调用的二义性,例如这段调用,编译会报错,因为无法区分应当调用重载函数中的哪一个,请务必要避免。
double d_Add(int n_NumA, int n_NumB, int n_Positive = 1, double d_Multiplier = 1.00);
double d_Add(int n_NumA, int n_NumB);
int main()
{
d_Add(200, 300);
return 0;
}
函数的嵌套
不妨思考这样一个题目,输入两个数$N,K$。求$Sum=1^K+2^K+3^K+ … +N^K$
不妨把这个过程分为两个子问题。
第一个子问题是求某个数的$K$次方,第二个子问题是将$1$到$N$的$K$次方加和得到$Sum$.
那么不难写出这样的代码:
#include <iostream>
using namespace std;
long long n_Pow(long long n_Num, long long n_K);
long long n_Sum(long long n_Range, long long n_K);
int main()
{
long long n_Num;
long long n_K;
long long n_Ans;
cin >> n_Num >> n_K;
n_Ans = n_Sum(n_Num, n_K);
cout << n_Ans << endl;
return 0;
}
long long n_Pow(long long n_Num, long long n_K)
{
long long n_Return = 1;
for (int i = 0; i < n_K; i++)
{
n_Return *= n_Num;
}
return n_Return;
}
long long n_Sum(long long n_Range, long long n_K)
{
long long n_Return = 0;
for (int i = 1; i <= n_Range; i++)
{
n_Return += n_Pow(i, n_K);
}
return n_Return;
}
这里我们就通过将任务分解成两个子任务,通过函数的嵌套完成了这个任务。
事实上,在C++的标准库中,已经有类似的函数完成了这个功能,求$x^y$可以直接调用<cmath>头文件中的double pow(double, double)函数。所以当我们调用这样的函数时,可以再对代码进行简化,就像这个样子:
#include <iostream>
#include <cmath>
using namespace std;
long long n_GetSum(long long n_Num, long long n_K);
int main()
{
long long n_Num;
long long n_K;
long long n_Ans;
cin >> n_Num >> n_K;
n_Ans = n_GetSum(n_Num, n_K);
cout << n_Ans << endl;
return 0;
}
long long n_GetSum(long long n_Num, long long n_K)
{
long long n_Return = 0;
for (long long i = 1; i <= n_Num; i++)
{
n_Return += (long long)pow(i, n_K);
}
return n_Return;
}
概念:地址
在程序运行时,变量存在于内存中,则其必定有一个对应的内存地址。
对于一个变量,其地址为所占的第一个字节的地址。
我们可以通过这样的代码来输出一个整型变量的内存地址。
#include <iostream>
using namespace std;
int main()
{
int n_A;
int n_B;
int n_C;
cout << &n_A << '\t' << &n_B << '\t' << &n_C;
return 0;
}
这段代码中”&”是对变量取地址的意思,所以运行这段代码得到的结果是(在不同PC上、不同时间上运行得到的结果并不唯一):
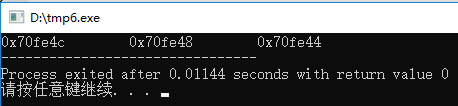
对于函数而言,函数是一段逻辑的有序组合。
在编译过程中,编译器先将源代码编译为.o文件,随后将.o文件编译为二进制指令集放在.exe等可执行文件中,而在运行可执行程序时,二进制指令集中的函数被加载到内存中,所以其实函数也是有地址的。
#include <iostream>
using namespace std;
int n_SampleFunc(int n_NumA, int n_NumB);
int main()
{
int (*n_Pointer)(int, int);
/*
Define a Integer Pointer which points to a Function Whose Return Type is Integer
while Having 2 Integer Arguments.
*/
n_Pointer = n_SampleFunc;
cout << n_Pointer;
return 0;
}
int n_SampleFunc(int n_NumA, int n_NumB)
{
return n_NumA + n_NumB;
}
上面这段示例代码展示了函数地址的查询方式。
函数的递归
递归是什么呢?
递归的定义:参见递归。
这个时候就有同学要问了:你这说了啥?
仔细看我们所讲的这一句话,其实就能明白递归所想要表达的含义,也就是在函数中调用自己。
这种调用方式适合用来做些什么事呢?
比如$n$的阶乘,其可以写作如下形式的递推格式:
$n!=(n-1)! * n$
那么当我们需要求$n$的阶乘时,只需要知道$(n-1)!$,再将其值乘上$n$就可以了,那么我们就需要再知道$(n-1)!$
欸?又是求阶乘,干的是同一件事!
那对于$(n-1)!$我们又可以用上面的方法逐项递推下去,直到求到$1!$那很显然就是1,那我们求到了1,再向上逐渐将结果递交上去,得到我们最终的结果。
写成代码的话就像这样:
#include <iostream>
using namespace std;
int n_Fact(int n_Num);
int main()
{
cout << n_Fact(5);
return 0;
}
int n_Fact(int n_Num)
{
return n_Num == 1 ? 1 : n_Fact(n_Num - 1) * n_Num;
}
那么还有什么问题可以用递归解决呢?
还记得裴波那契数列吗?
$1, 1, 2, 3, 5, 8, …$
对于裴波那契数列,其有这样的递推公式:
$a_1 = 1, a_2= 1,a_n=a_{n-1}+a_{n-2}$
所以用递归方式求裴波那契数列第$n$项的代码可以像这样写(我们假设求的是第$20$项):
#include <iostream>
using namespace std;
int n_Fibbonaci(int n_Num);
int main()
{
cout << n_Fibbonaci(20);
return 0;
}
int n_Fibbonaci(int n_Num)
{
return n_Num <= 2 ? 1 : n_Fibbonaci(n_Num - 1) + n_Fibbonaci(n_Num - 2);
}
内联函数
内联函数适用于函数内逻辑较简单的函数。
在编译时,编译器会直接在主函数中内联函数的调用直接替换为函数体的内容,减少主函数中代码量,以提升代码可读性。
例如:
#include <iostream>
using namespace std;
inline int add(int a, int b) {return a + b;}
int main()
{
cout << add(1, 2) << endl;
return 0;
}
这段代码中,编译时,编译器会直接将"add(1, 2)"替换为"1+2",而不会将内联函数编译到内存中。
作用域
这里我们额外讲解一下变量的分类(后续会做更详细的补充,详细内容请查看发布合并后的主文档):
变量分为普通变量和静态变量,静态变量的关键字是"static"
普通变量的管理是放在为程序分配的内存栈中,而静态变量的管理是放在变程序分配的内存堆中。
栈和堆各是数据结构中的一种,在后续的数据结构课程中会讲到。
我们用一段伪代码来理解作用域的问题:
// School
int x;
{
// Building
int y;
{
// Classroom
int z;
{
// Desk
int w;
}
}
}
把最外侧的区域比作是一整个学校,我们在学校里可以找到$x$同学,但因为教学楼是对里面锁着的,$y$同学没法从教学楼里出来找$x$同学玩,但$x$可以进入教学楼找$y$,同理,因为教室是对里面锁着的,$z$没有办法从教室出来找$y$,更没法从教学楼出来找到外面的$x$,但是$x$和$y$都可以进到教室里找到$z$,以此类推,桌子中的宠物$w$不能从锁着的桌子中出来找到$x,y,z$,但$x,y,z$能打开桌子看到$w$并和它互动。
这就是为什么没法在//Building区域对$z$或$w$赋值,但可以给$x$赋值的原因。
值传递与对象传递(引用)
我们来看一段代码,其实现的是交换两个数的值。
#include <iostream>
using namespace std;
void swap(int a, int b);
int main()
{
int a = 10;
int b = 20;
swap(a, b);
cout << a << ' ' << b << endl;
return 0;
}
void swap(int a, int b)
{
int c = a;
a = b;
b = c;
return;
}
运行的结果是:
10 20
在swap函数里我们不是已经交换a和b了吗?
这里就涉及到一个问题了,我们通过参数传入函数的只是这两个变量的值,而在函数运行的过程中只是将传入的有这两个值的变量交换了值,而并没有改变主函数中变量的值,因此主函数中a和b的值从头到尾就没有被改变,所以才会出现没有交换值的结果。
那如果我们要让这个函数实现交换的功能呢?
实际上,我们只需要进行一点小小的修改,就可以做到这个功能,看看下面这段代码与上面的区别:
#include <iostream>
using namespace std;
void swap(int &a, int &b);
int main()
{
int a = 2;
int b = 3;
swap(a, b);
cout << a << ' ' << b << endl;
return 0;
}
void swap(int &a, int &b)
{
int c = a;
a = b;
b = c;
return;
}
在这段代码中,我们使用了“引用”特性,即swap中的两个参数传入的是两个变量对象,而并非这两个变量的值,对传入的两个变量对象进行操作,也就相当于是对主函数中这两个变量对象进行操作,就可以完成交换其值的操作。
运行这段代码得到的结果就是正确的:
3 2
引用的本质就是指针,解决指针的间接访问的问题。
int i;
int & refi = i; // It Should be initialized upon declaration, Always used when declaring a function.
int & ref = * new int;
delete & ref;
详细内容请见之前的总结。
外部变量(extern关键字)
在多文件工程中,我们使用extern关键字标识某变量不仅在其所属的文件中可以使用,而且还可以在其他文件中使用,在项目中,我们来看一看这样的代码。
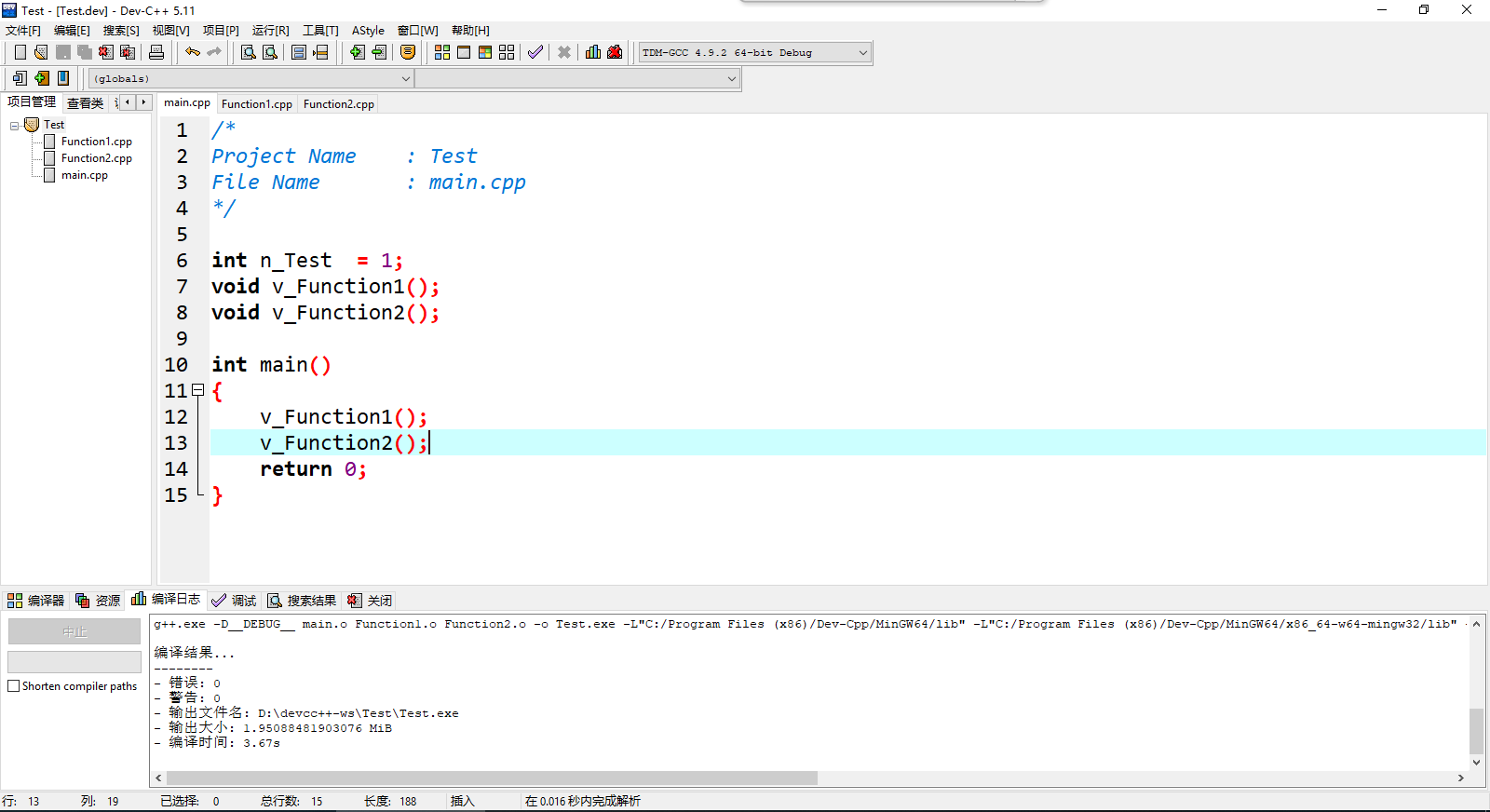
/*
Project Name : Test
File Name : main.cpp
*/
int n_Test = 1;
void v_Function1();
void v_Function2();
int main()
{
v_Function1();
v_Function2();
return 0;
}
/*
Project Name : Test
File Name : Function1.cpp
*/
#include <iostream>
using namespace std;
void v_Function1()
{
extern int n_Test;
cout << "Function 1: " << ++n_Test << endl;
return;
}
/*
Project Name : Test
File Name : Function2.cpp
*/
#include <iostream>
using namespace std;
void v_Function2()
{
extern int n_Test;
cout << "Function 2: " << ++n_Test << endl;
}
在项目中我们可以创建多个cpp文件,只有一个main入口,在main.cpp中声明函数,用其他cpp文件对这些函数进行实现。就像图中这样:
工程管理
一般来说,对于一个多文件工程,我们需要将函数的声明放到“头文件”中,这里头文件充当了清单的作用,也就是列出这个工程中我单独声明的函数的列表,并且对于这个头文件,我们创建一个同名的cpp文件对函数进行实现,这样当我们在创建main.cpp作为我们的主文件时,我们就只需要包含头文件,然后直接调用函数就可以实现这样的功能,并且main.cpp中我们可以清晰地看到程序的逻辑,非常简单。
对于刚才的交换函数,我们可以用这样的方式进行工程管理,如下图所示,这分别是myfunction.h文件中对函数的声明,以及myfunction.cpp文件中对这个函数的实现。
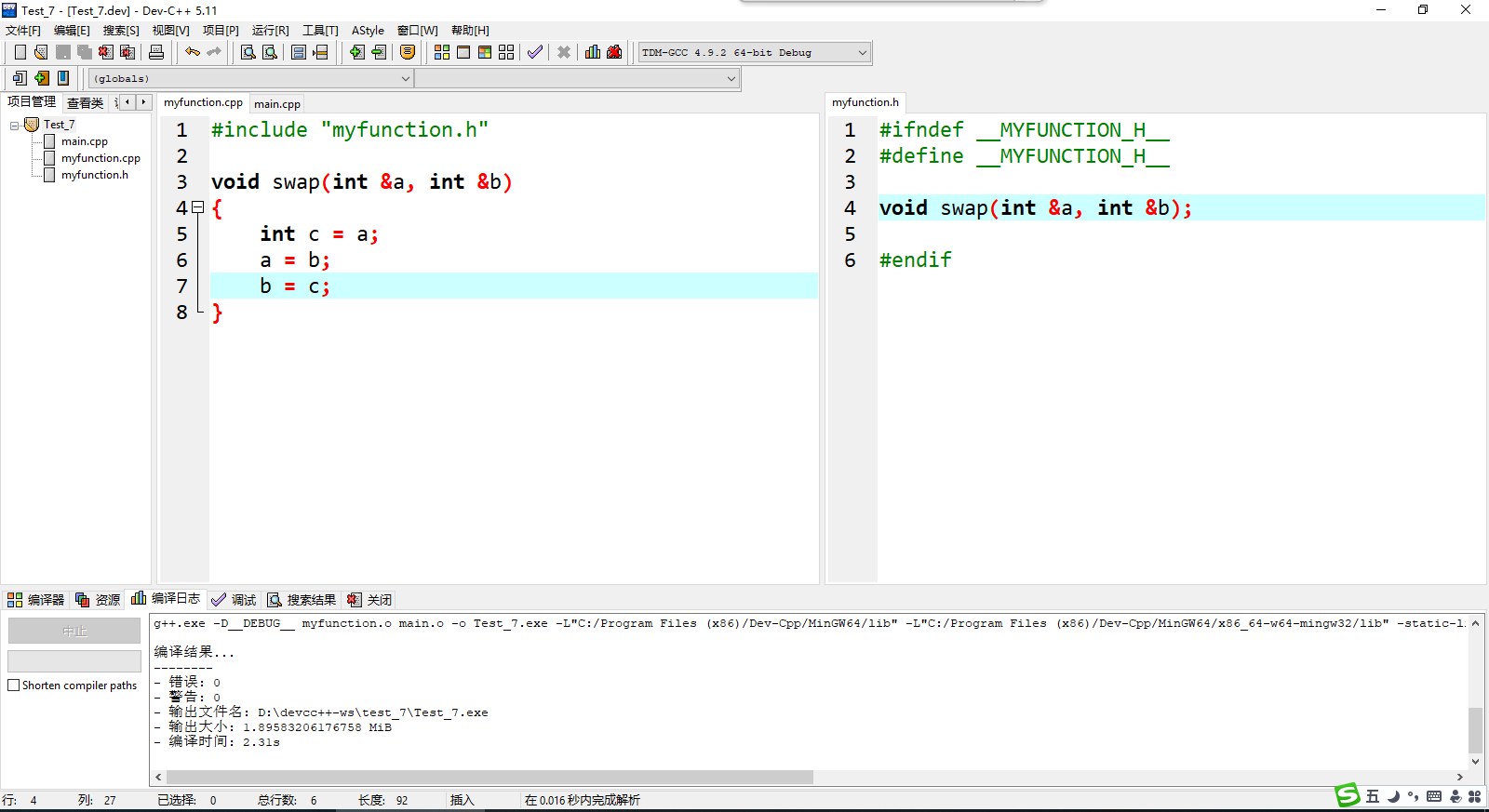
这里解释一下头文件开头的:
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
// Do something
#endif
在程序设计中,为了防止我们重复包含头文件,在书写头文件时,这段代码表示的意思是:
当”__MYFUNCTION_H__“未被定义,则定义”__MYFUNCTION_H__“并在#endif之前进行函数声明,否则直接跳到#endif处,这样当一个头文件被多次包含,这些函数也只会被声明一次,以防出现重复声明的问题。
而main.cpp中我们将myfunction.h包含进来之后进行主函数的编写。
这样我们所看到的这段主函数代码就非常清爽了。
静态成员变量(static关键字)
在刚才的swap函数中,如果我们想要统计swap的执行次数,可以在swap函数中定义一个静态成员变量count,我们可以看一看这个程序:
#include <iostream>
using namespace std;
void swap(int &a, int &b);
int main()
{
int x = 10;
int y = 20;
while(x > 0)
{
swap(x, y);
x--;
}
return 0;
}
void swap(int &a, int &b)
{
int count = 0;
int c = a;
a = b;
b = c;
count++;
cout << count << endl;
}
我们运行这段代码,看看得到了什么结果?
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
为什么全是1?
因为每次运行swap函数时,都会重新申请一个count并初始化其值为0,运行完之后对其进行增加操作,所以每次都只会输出1。
当我们对count加上了static限定其为静态成员变量,当这个函数被反复调用时,该变量只会申请一次内存,像下面这样。
#include <iostream>
using namespace std;
void swap(int &a, int &b);
int main()
{
int x = 10;
int y = 20;
while(x > 0)
{
swap(x, y);
x--;
}
return 0;
}
void swap(int &a, int &b)
{
static int count = 0;
int c = a;
a = b;
b = c;
count++;
cout << count << endl;
}
这样的运行结果就是正确的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
预编译
为编译器进行预处理的过程。
包含指令(#include)
这种指令其实同学们已经很熟悉了,其主要作用是将头文件中函数声明相关的内容放进文件中,以使主函数中对函数的调用能正常执行,详细可以参照之前我们讲解”extern”关键字时的项目。
包含指令既可以使用尖括号,也可以使用双引号,尖括号表示先在C和C++的库目录中寻找,再在工作目录中寻找该头文件,引号则恰好相反。
其他宏指令
文本替换(#define)
格式:
#define NAME DESCRIPTION
这里NAME字段不允许有空格,预编译时会把NAME替换为后面的DESCRIPTION的内容。
这样做的目的是为了让代码变得更加清晰可读。不过也不要乱用这样的指令,比如接下来的这段代码,如果编译会提示内存耗尽,无法正常完成编译。
不要将这段代码用在实际的项目中!// Don't do this in real project!
#define A B B
#define B C C
#define C D D
#define D E E
#define E F F
#define F G G
#define G H H
#define H I I
#define I J J
#define J K K
#define K L L
#define L M M
#define M N N
#define N O O
#define O P P
#define P Q Q
#define Q R R
#define R S S
#define S T T
#define T U U
#define U V V
#define V W W
#define W X X
#define X Y Y
#define Y Z Z
#define Z A A
int main()
{
int A;
return 0;
}
这里有很多文本替换指令,其作用是将找到的”A”替换为”B B”,将找到的”B”替换为”C C”…再将找到的”Z”替换为”A A”。
当编译器在找到A时,就会将其无限替换,进入死循环,直到内存溢出,停止编译,编译是不成功的。
让我们来看一段正确使用#define指令的代码:
#include <iostream>
#define STU_NUM 30
using namespace std;
int main()
{
for (int i = 0; i < STU_NUM; i++)
{
cout << i << ' ';
}
cout << endl;
for (int j = 0; j < STU_NUM; j++)
{
cout << j << ' ';
}
return 0;
}
这里我们将STU_NUM用文本替换指令统一替换为30,非常清爽,同时我们通过这个宏定义知道这个常数是表示学生数量的。
带宏定义的编译,示例:
#include <iostream>
#define X86
using namespace std;
int main()
{
#ifdef X86
cout << "x86" << endl;
#elif defined ARM64
cout << "ARM64" << endl;
#else
cout << "unknown" << endl;
#endif
#undef X86
return 0;
}
这里只会输出:
x86
而其他代码不会被编译。
带参宏
直接以代码示例:
#include <iostream>
#define ADD(a,b) a+b
using namespace std;
int main()
{
cout << ADD(2,3)*ADD(2,3) << endl;
return 0;
}
运行结果为:
11
运行过程相当于:
2+3*2+3
所以为了防止这样的情况出现,我们最好在带参宏后加上括号(括号真的不要钱)
#define ADD(a,b) (a+b)
数组
为什么我们会需要使用数组呢?
我们回想一下之前进制转换的问题,如果我们不使用移位运算,直接用短除法不断得到该进制数的末位的值,将得到末位的值输出出来的话,与实际的数值恰好是反向的,但倘若我们直接用一个数据结构将这一串数存下来,并在需要它的时候将其按正确的顺序输出,那就简单多了。
所以说,我们引进数组:
int a[5]; // Define an Array Containing 5 integers and its name "a"
数字的定义格式:
Type Array_Name[Array_Size];
需要注意的是,在实际代码中,Array_Name指的是该数组在内存中占用的首个地址。
而数组中具体第$k$项所对应的内存地址就是首地址向后偏移k * sizeof(Type)个字节。
访问数组时就直接使用a[i]就能访问数组a中的第i个元素。
数组元素的地址的表示可以通过如下两个为真的表达式进行理解。
&a[0] == a;
&a[i] == a + sizeof(int) * i;
数组元素的赋值方式:
int a[5];
a[2] = 10;
数组元素的初始化方式:
int a[5] = {0, 1, 2, 3, 4}; // Correct
int a[5] = {0, 1, 2, 3, 4, 5}; // Illegal
int a[5] = {0, 1, 2}; // Correct
int a[5] = {0, 1, 2, 0, 0}; // Correct, Same with the statement above
int a[5] = {0}; // Correct, All Elements are Set to 0
int a[5] = 0; // Correct, Same with the statement above
用循环方式:
int main()
{
int a[5];
for (int i = 0; i < 5; i++)
{
a[i] = 0;
}
return 0;
}
用更暴力的内存赋值方式:
#include <cstring> // To Use Function memset()
int main()
{
int a[5];
memset(a, 0, sizeof(a));
memset(a, 0, sizeof(int) * 5); // Both Statements have the same function.
return 0;
}
需要注意的是,内存赋值是直接对所有对应地址的字节赋同一个值。
如果没有在定义时指定数组的大小,但进行了初始化,数组的长度默认为后续已被初始化的个数。例如下面两种定义是等价的。
int a[] = {0, 1, 2, 3, 4};
int a[5] = {0, 1, 2, 3, 4};
虽然可以用变量指定数组大小,但安全起见,我们一般会使用常量填入。
// First Kind of Declaration
int a[5];
// Second Kind of Declaration
const int N = 5;
int b[N];
// Third Kind of Declaration
#define ARRY_LEN 5
int c[ARRY_LEN];
上述3种定义都是合理且安全的,但请避免使用下面这一种定义方式,使用变量定义数组长度时,会出现很多不可控的情况,比如内存未正常回收的问题。
// Fourth Kind of Declaration
/* DO NOT USE THIS KIND OF DECLARATION
OR IT WILL CAUSE MEMORY LEAK, MAKING THINGS OUT OF CONTROL */
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int a[n];
n = 0;
return 0;
}
如果一定要使用这种方式,请参照如下代码,以保证内存能被正常回收。
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
const int m = n;
int a[m]; // m is const, so it's safe when releasing memory
n = 0;
return 0;
}
将数组作为函数参数进行传递
在2024年11月15日的课前代码练习中,我们对数组进行了多个操作,如果我们将这些操作封装成函数。在多文件项目中,我们可以这样实现。
// Project : Test
// File : MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
/* a[] Refer to the Starting Address of the Array
n Refer to the Total Amount of Elements in Array a. */
void Array_Init(int a[], int n);
void Array_Show(int a[], int n);
void Array_Analyze(int a[], int n);
#endif
// Project : Test
// File : MyFunction.cpp
#include "MyFunction.h"
void Array_Init(int a[], int n)
{
srand(time(NULL));
for (int i = 0; i < n; i++)
{
a[i] = rand() % 101;
}
return;
}
void Array_Show(int a[], int n)
{
for (int i = 0; i < n; i++)
{
cout << a[i] << ' ';
}
cout << endl;
return;
}
void Array_Analyze(int a[], int n)
{
int count = 0;
int sum = 0;
for (int i = 0; i < n; i++)
{
if (a[i] % 2)
{
count++;
sum += a[i];
}
}
cout << count << endl;
cout << (double)sum / (double)count << endl;
}
// Project : Test
// File : main.cpp
#include "MyFunction.h"
#define ARRAY_LEN 10
int main()
{
int a[ARRAY_LEN] = {0};
Array_Init(a, ARRAY_LEN);
Array_Show(a, ARRAY_LEN);
Array_Show(a + 5, ARRAY_LEN - 5); // Show the Last 5 Element of the Array
Array_Analyze(a, ARRAY_LEN);
return 0;
}
注意带注释的那行代码的意思,这里代表的是将a[5](也就是第6个元素)的地址传入作为数组的首地址,长度为ARRAY_LEN - 5也就是5,对其进行展示。
这段代码的运行结果是:
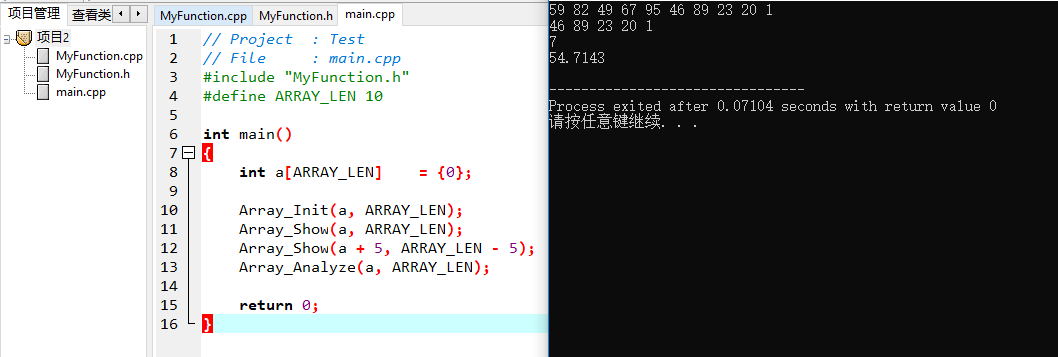
可以看到,这里的展示是将数组的下标为5, 6, 7, 8, 9(也就是第6, 7, 8, 9, 10个元素)输出。
这里是最容易让人犯迷糊的地方,请务必要注意数组的下标和数组的第几个元素的区别,以避免可能出现的**越界访问问题**。越界读写行为均不可控。
数组的应用
排序
选择排序
选定第一个数为基准,从前之后依次进行比较,如果发现有比它更小(大)的,则将其作为基准数,并将其放置在数组的最开头(或最末尾)。
我们用一个数组来示例以将一个长度为6的数组通过选择排序得到一个升序数组的过程。
Initial Array
6 1 3 2 5 4
^
选定6作为基准数,从前至后依次找是否有比6更大的
6 1 3 2 5 4
^
找到最后发现没有数比6更大,6与最后一个数交换,此时6就到数组尾部,已经归位,之后不再考虑6。
4 1 3 2 5 6
^
选定4作为基准数,从前至后依次找是否有比4更大的。
4 1 3 2 5 6
^
找到5比4大,找到最后将5与最后一个数交换,此时5就到未排序的数组尾部,已经归位,之后不再考虑5。
4 1 3 2 5 6
^
以此类推,接下来的过程如下,这里"^"指向的就是每次寻找结束后我们所得到的最大的数。
4 1 3 2 5 6
^
2 1 3 4 5 6
^
2 1 3 4 5 6
^
1 2 3 4 5 6
^
1 2 3 4 5 6
最后得到的就是已经排序好的数组。
代码实现:
// Project : Test
// File : MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
void Array_Init(int a[], int n);
void Array_Show(int a[], int n);
void Array_Sort_Select(int a[], int n);
#endif
// Project : Test
// File : MyFunction.cpp
#include "MyFunction.h"
void Array_Init(int a[], int n)
{
srand(time(NULL));
for (int i = 0; i < n; i++)
{
a[i] = rand() % 101;
}
return;
}
void Array_Show(int a[], int n)
{
for (int i = 0; i < n; i++)
{
cout << a[i] << ' ';
}
cout << endl;
return;
}
void Array_Sort_Select(int a[], int n)
{
int MaxValue = 0;
int Index = 0;
for (int i = 0; i < n; i++)
{
MaxValue = a[0];
Index = 0;
for (int j = 0; j < n - i; j++)
{
if (a[j] > MaxValue)
{
MaxValue = a[j];
Index = j;
}
}
int Tmp = a[Index];
a[Index] = a[n - i - 1];
a[n - i - 1] = Tmp;
}
return;
}
// Project : Test
// File : main.cpp
#include "MyFunction.h"
const int SIZE = 10;
int main()
{
int a[SIZE];
Array_Init(a, SIZE);
Array_Show(a, SIZE);
Array_Sort_Select(a, SIZE);
Array_Show(a, SIZE);
return 0;
}
下面是这段代码运行的结果。
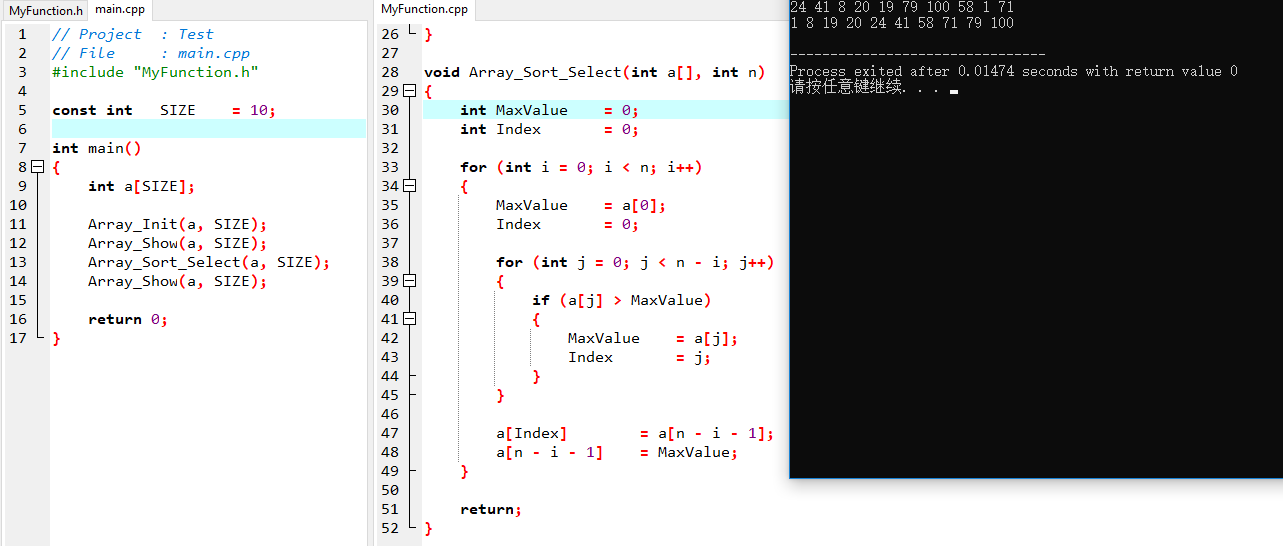
冒泡排序
对于这样的一组数,从前至后两两比较,如果发现后面比前面大,那么就将两个数交换。
Initial Array
5 8 2 7 9 3
Round 1:
5 8 2 7 9 3
^ ^
8比2大,交换
5 2 8 7 9 3
^ ^
8比7大,交换
5 2 7 8 9 3
^ ^
9比3大,交换
5 2 7 8 3 9
^
此时9已经归到正确的位置
Round 2:
5 2 7 8 3 9
^ ^
5比2大,交换
2 5 7 8 3 9
^ ^
8比3大,交换
2 5 7 3 8 9
^
此时8已经归到正确的位置
Round 3:
2 5 7 3 8 9
^ ^
7比3大,交换
2 5 3 7 8 9
^
此时7已经归到正确的位置
Round 4:
2 5 3 7 8 9
^ ^
5比3大,交换
2 3 5 7 8 9
^
此时5已经归到正确的位置
Round 5:
2 3 5 7 8 9
^ ^
符合要求,不做交换
最后的数组就是
2 3 5 7 8 9
那么代码实现如下:
// Project: Test
// File: MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
void Array_Init(int a[], int n);
void Array_Show(int a[], int n);
void Array_Sort_Bubble(int a[], int n);
#endif
// Project: Test
// File: MyFunction.cpp
#include "MyFunction.h"
void Array_Init(int a[], int n)
{
srand(time(NULL));
for (int i = 0; i < n; i++)
{
a[i] = rand() % 101;
}
return;
}
void Array_Show(int a[], int n)
{
for (int i = 0; i < n; i++)
{
cout << a[i] << ' ';
}
cout << endl;
return;
}
void Array_Sort_Bubble(int a[], int n)
{
int tmp;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (a[j] > a[j + 1])
{
tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
return;
}
// Project: Test
// File: main.cpp
#include "MyFunction.h"
const int SIZE = 10;
int main()
{
int a[SIZE];
Array_Init(a, SIZE);
Array_Show(a, SIZE);
Array_Sort_Bubble(a, SIZE);
Array_Show(a, SIZE);
return 0;
}
二分查找
对于一个已经排列好的数组,我们可以通过二分查找的方式提高找到该数组的平均速度。
Initial Array:
2 3 5 7 8 9
Target: 8
Round 1:
2 3 5 7 8 9
^
检查: 8 > 5
目标数在右半序列中
Round 2:
2 3 5 7 8 9
^
检查: 8 > 7
目标数在剩余的右半序列中
Round 3:
2 3 5 7 8 9
^
检查: 8 = 8
找到了目标数
代码实现如下:
// Project : Test
// File : MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
void Array_Init(int a[], int n);
void Array_Show(int a[], int n);
void Array_Sort_Bubble(int a[], int n);
int Array_Binary_Search(int a[], int n, int target);
#endif
// Project : Test
// File : MyFunction.cpp
#include "MyFunction.h"
void Array_Init(int a[], int n)
{
srand(time(NULL));
for (int i = 0; i < n; i++)
{
a[i] = rand() % 101;
}
return;
}
void Array_Show(int a[], int n)
{
for (int i = 0; i < n; i++)
{
cout << a[i] << ' ';
}
cout << endl;
return;
}
void Array_Sort_Bubble(int a[], int n)
{
int tmp;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (a[j] > a[j + 1])
{
tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
return;
}
int Array_Binary_Search(int a[] ,int n, int target)
{
int left = 0;
int right = n - 1;
int mid;
while (left <= right)
{
mid = (left + right) / 2;
if (a[mid] == target)
{
return mid;
}
if (left == right)
{
return -1;
}
if (a[mid] < target)
{
left = mid + 1;
continue;
}
if (a[mid] > target)
{
right = mid - 1;
continue;
}
}
}
// Project : Test
// File : main.cpp
#include "MyFunction.h"
const int SIZE = 10;
int main()
{
int a[SIZE];
int Find;
int Result;
Array_Init(a, SIZE);
Array_Show(a, SIZE);
Array_Sort_Bubble(a, SIZE);
Array_Show(a, SIZE);
cin >> Find;
Result = Array_Binary_Search(a, SIZE, Find);
if (Result == -1)
{
cout << "Not Found The Requested Number " << Find << "." << endl;
}
else
{
cout << "Number " << Find << " is Found at Position " << Result << "." << endl;
}
return 0;
}
程序运行结果为:
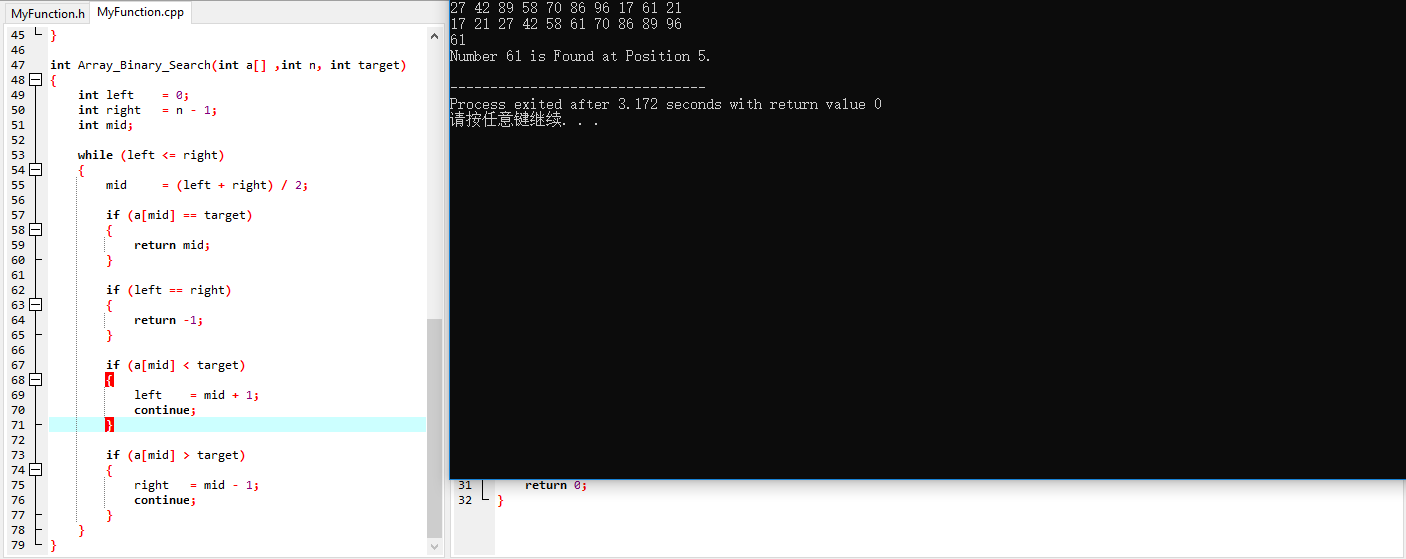
还有一种递归的写法,如下所示:
int Array_Binary_Search(int a[], int left, int right, int target)
{
if (left > right)
{
return -1;
}
int mid = (left + right) / 2;
if (a[mid] == target)
{
return mid;
}
if (a[mid] > target)
{
return Array_Binary_Search(a, left, mid - 1, target);
}
if (a[mid] < target)
{
return Array_Binary_Search(a, mid + 1, right, target);
}
}
二维数组
用二维数组对数据进行存储,定义方式:
Type Array_Name[Array_Size][Array_Size];
初始化方式:
int a[4][4] = {{10, 11},
{20, 21, 22, 23},
{0, },
{40, 41, 42, 43}}; // Valid
int b[4][4] = {{10, 11, 0 , 0 },
{20, 21, 22, 23},
{0 , 0 , 0 , 0 },
{40, 41, 42, 43}}; // Valid, Array b is completely the same with Array a
int c[4][4] = {1, 2, 3, 4, 5, 6, 7, 8}; // Valid, treat 2-dimension array as a 1-dimension array.
代码实现如下:
// Project : Test
// File : MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
const int ROW = 4;
const int COL = 4;
const int Upper_Limit = 101;
void Array_Init(int a[][COL], int Row);
void Array_Show(int a[][COL], int Row);
#endif
// Project : Test
// File : MyFunction.cpp
#include "MyFunction.h"
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
void Array_Init(int a[][COL], int Row)
{
srand(time(NULL));
for (int i = 0; i < Row; i++)
{
for (int j = 0; j < COL; j++)
{
a[i][j] = rand() % Upper_Limit + 1;
}
}
return;
}
void Array_Show(int a[][COL], int Row)
{
for (int i = 0; i < Row; i++)
{
for (int j = 0; j < COL; j++)
{
cout << a[i][j] << ' ';
}
cout << endl;
}
return;
}
// Project : Test
// File : main.cpp
#include "MyFunction.h"
int main()
{
int a[ROW][COL];
Array_Init(a, ROW);
Array_Show(a, ROW);
return 0;
}
字符数组
我们可以通过字符数组来存储一个字符串,声明及初始化方式如下。
char ch[10] = {104, 101, 108, 108, 111}; // Valid
char ch[10] = {'h', 'e', 'l', 'l', 'o'}; // Valid, clearer than previous one
char ch[10] = "hello"; // Valid, even clearer
char ch[101] = "Hello \0 World."; // Valid, but if considered as string, it is considered "hello "
因为字符串末尾会以\0表示字符串结束,所以在存储一个5个字符的字符串时,至少应该申请6个字符的字符数组。输出字符串时,直接cout << ch即可。
示例代码:
#include <iostream>
using namespace std;
int main()
{
char ch[101] = {'h', 'e', 'l', 'l', 'o'};
cout << ch << endl;
for(int i = 0; i < 101; i++)
{
cout << (int)ch[i] << ' ';
}
cout << endl;
for (int i = 0; i < 101; i++)
{
cout.put(ch[i]);
}
cout << endl << sizeof(ch);
return 0;
}
在<cstring>头文件中,有几个函数可以用于对字符串进行处理,如下。
strlen()函数
用于获取字符数组中有效字符的个数(从首位统计至第一个'\0',看第一个'\0'之前一共有多少个字符),例程:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello world";
int len = strlen(ch);
cout << len << endl;
return 0;
}
对应的,对于这段例程来说,输出的结果是:
11
而如果我们改成这样的代码,统计出来的字符数就会和之前有所不同:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello\0 world";
int len = strlen(ch);
cout << len << endl;
return 0;
}
对于这段例程来说,输出的结果就是:
5
但这并非代表我们字符数组中'\0'以后的数都没有存入,如果我们通过for循环强制输出字符串中的每一个字符,我们还是可以看到'\0'后的字符。
strcpy()函数
将第二个参数对应的字符串中的'\0'及之前的内容拷贝进入第一个字符串中。
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101];
char dest[101];
strcpy(ch, "hello world");
strcpy(dest, ch);
cout << ch << endl;
cout << dest << endl;
return 0;
}
输出的结果是:
hello world
hello world
倘若我们只要"world",那么我们就可以更改传入的始地址。
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101];
char dest[101];
strcpy(ch, "hello world");
strcpy(dest, "xxxxxxxxxxxx");
strcpy(dest + 6, ch + 6);
cout << dest << endl;
return 0;
}
这样的输出就是:
xxxxxxworld
strncpy()函数
与strcpy()功能相同,不过多了一个参数可以指定拷贝源字符串中的多少个字符。
我们用下面这段程序了解一下strcpy()的局限性:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello world";
char dest[5];
strcpy(dest, ch);
// Illegal. This will visit memory which is not assigned to char array dest[5]
cout << dest << endl;
return 0;
}
虽然这样的程序仍然能正确输出hello world,但因为非法访问了其他内存,可能会导致不确定的问题。
对应的,如果我们使用strncpy()函数进行拷贝,可以在拷贝的过程中指定拷贝的字符数,防止可能的非法访问。
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello world";
char dest[5];
strcpy(dest, ch, 4);
cout << dest << endl;
return 0;
}
memcpy()函数
```C++
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello world";
char dest[101];
memcpy(dest, ch, 12);
return 0;
}
这段代码的意思是将ch数组的前12个字节的内容拷贝到dest的前12个字节中。
运行代码输出的结果是:
hello world
strcat()函数
```C++
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello world";
char dest[5] = "wow!";
strcat(ch, dest);
cout << ch << endl;
return 0;
}
输出结果:
hello worldwow!
同样需要注意是否有非法内存访问的问题,这里不再额外进行解释。
strncat()函数
```C++
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[101] = "hello world";
char dest[5] = "wow!";
strcat(ch, dest, 2);
cout << ch << endl;
return 0;
}
输出的结果是:
hello worldwo
strcmp()函数
用于比较两个字符串,分别通过字符串长度、每一项具体对应的ASCII码值大小进行比较,得到结果。
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
cout << strcmp("hello world", "hello world") << endl;
cout << strcmp("hallo world", "hello world") << endl;
cout << strcmp("hhllo world", "hello world") << endl;
}
输出结果为
0
-1
1
strcmp()返回值 |
表示含义 |
|---|---|
| 0 | 两字符串完全相同 |
| -1 | 第一个字符串的长度比第二个字符串长度小,或者两者长度相同,但从左到右依次对比时,第一个不相同的字符,第一个字符串的该字符小于第二个字符串的该字符 |
| 1 | 第一个字符串的长度比第二个字符串长度大,或者两者长度相同,但从左到右依次对比时,第一个不相同的字符,第一个字符串的该字符大于第二个字符串的该字符 |
strncmp()函数
用于比较两个字符串的前$n$个字符。
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
cout << strncmp("9241608403", "9241068402", 8) << endl;
return 0;
}
输出的结果是
0
参考前文中strcmp()返回值的意义表格,可以得出这两个字符串前8位相同的结论。
部分函数的重新实现
我们可以自己重新写一遍这些函数,来更深体会这些函数的作用。
// Project : Test
// File : MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
int mystrlen(char source[]);
void mystrcat(char dest[], char source[]);
#endif
// Project : Test
// File : MyFunction.cpp
#include "MyFunction.h"
#include <cstring>
int mystrlen(char source[])
{
int n_Cnt = 0;
while (source[n_Cnt])
{
n_Cnt++;
}
return n_Cnt;
}
void mystrcat(char dest[], char source[])
{
int n_Length = mystrlen(dest);
int i = 0;
while (source[i])
{
dest[i + n_Length] = source[i];
i++;
}
dest[i + n_Length] = '\0';
return;
}
// Project : Test
// File : main.cpp
#include "MyFunction.h"
#include <iostream>
using namespace std;
int main()
{
char ch1[101] = "String1 ";
char ch2[101] = "String2";
mystrcat(ch1, ch2);
cout << ch1 << endl;
return 0;
}
运行结果为:
String1 String2
字符串的输入
逐字符读入时可以使用cin.get()函数,如下所示。
#include <iostream>
using namespace std;
int main()
{
char ch[101];
int n_Cnt = 0;
while (1)
{
cin.get(ch[n_Cnt]);
if (ch[n_Cnt] == 'q') // Set 'q' as a flag for the end of a string
{
ch[n_Cnt] = '\0';
break;
}
n_Cnt++;
}
cout << ch << endl;
return 0;
}
逐行读入可以使用cin.getline()函数,如下所示。
#include <iostream>
using namespace std;
int main()
{
char ch[101];
cin.getline(ch, 100); // Read a line of text with a maximum length of 100 (including '\0')
cout << ch << endl;
return 0;
}
这里代表的是读入一行最长为100(包含'\0')的字符串,并存储至字符数组ch中。
逐个字符串读入可以直接使用cin。
#include <iostream>
using namespace std;
int main()
{
char ch[101];
cin >> ch;
cout << ch << endl;
return 0;
}
比如这样输入时:
String1 String2
这段代码只会输出:
String1
结构体 (已有类型的组合体)
将同一对象的不同属性打包成一种结构存储。下面是一个结构体定义的示例:
struct Person
{
char SN[13]; // SN stands for Serial Number.
char name[10]; // name stands for Student's name.
bool gender; // 1 for Male, 0 for Female.
unsigned char height; // Accept integers ranged from 0-255, unit: Centimeter
unsigned short weight; // Accept integers ranged from 0-511, unit: Kilogram
}; // Declaration
Person a; // Definition
Person b = {"924106840701", "Sample", 1, 173, 70}; // Definition with Initialization
memset(&b, 0, sizeof(b)); // Initialize Person b with all its value set to 0
如果需要访问或修改结构体中的成员变量的值,可以像这样进行:
Person a;
a.weight = 70;
cout << a.height << endl;
枚举和内存对齐
对于一种特定属性,可以通过“枚举”列举出其所有可能取到的情况,用来代替之前我们通过bool gender;这样代指的情况,可以理解enum指定了一种新的变量类型,其值域空间仅为后续列出的变量索引。
如果不特别指定枚举所代表的索引值,那么枚举中变量的索引默认从0开始,否则从第一个代表的值开始赋值,后续的索引依次+1.
让我们来看这样一段代码:
#include <iostream>
using namespace std;
typedef unsigned char uint_8 ;
typedef unsigned short uint_16;
typedef unsigned int uint_32;
enum Gender
{
Male, Female, Others
};
struct Student
{
char StuID[20]; // 20 Bytes
char Name[20]; // 20 Bytes
uint_8 Year; // 1 Byte
Gender Gend; // 4 Bytes
float Height; // 4 Bytes
float Weight; // 4 Bytes
int Score; // 4 Bytes
};
int main()
{
cout << sizeof(Student) << endl;
return 0;
}
运行这段程序,根据我们在代码中的注释应该输出的是
$20 + 20 + 1 + 4 + 4 + 4 + 4 = 57 (Bytes)$
但实际输出的结果是:
60
为什么会这样呢?
这里展示的特性是“内存对齐”。在无特别说明时,struct类型申请的内存默认按$4$个字节对齐,所以说我们虽然申请了$57$个字节的内存,但实际上得到的就是$60$个字节的内存。
如果我们不想要这样浪费内存,可以通过预编译指令表示字节对齐的数量。
#include <iostream>
using namespace std;
#pragma pack(1) // Set to 1 Byte
typedef unsigned char uint_8 ;
typedef unsigned short uint_16;
typedef unsigned int uint_32;
enum Gender
{
Male, Female, Others
};
struct Student
{
char StuID[20]; // 20 Bytes
char Name[20]; // 20 Bytes
uint_8 Year; // 1 Byte
Gender Gend; // 4 Bytes
float Height; // 4 Bytes
float Weight; // 4 Bytes
int Score; // 4 Bytes
};
int main()
{
cout << sizeof(Student) << endl;
return 0;
}
#pragma pack() // Reset to 4 Bytes (default)
这样输出的结果就是我们需要的一点都不浪费内存的:
57
结合之前我们学习的结构体和函数,我们可以通过这样的代码练习:
#include <iostream>
using namespace std;
typedef unsigned char uint_8 ;
typedef unsigned short uint_16;
typedef unsigned int uint_32;
enum Gender
{
Male, Female, Others
};
struct Student
{
char StuID[20];
char Name[20];
uint_8 Year;
Gender Gend;
float Height;
float Weight;
int Score;
};
void v_StuPrint(Student & Stu);
int main()
{
Student Stu_A = {"924106840701", "Sample", 20, Male, 60.1, 173.0, 59};
v_StuPrint(Stu_A);
return 0;
}
void v_StuPrint(Student & Stu)
{
cout << Stu.StuID << endl
<< Stu.Name << endl
<< (int)Stu.Year << endl
<< Stu.Gend << endl
<< Stu.Height << endl
<< Stu.Weight << endl
<< Stu.Score << endl;
return;
}
运行的结果是:
924106840701
Sample
20
0
60.1
173
59
再次强调,不允许直接将字符串常量赋给字符数组。
// THE CODE BELOW IS NOT ALLOWED, IT WILL RESULT IN COMPILE ERROR!
Stu.StuID = "924106840701";
结构体数组与数组用法类似,此处不再多讲。
typedef关键字
在之前我们已经提到过,typedef关键字可以为变量新增一个别名,可以用这样的别名来声明和使用该类变量,主要是用于将变量名简化。
例如之前我们讲的内容:
typedef unsigned char uint_8 ;
typedef unsigned short uint_16;
typedef unsigned int uint_32;
using关键字
用于声明所使用的命名空间,也就是说这是谁家的函数。
#include <iostream>
using namespace std;
int main()
{
cout << "Hello World" << endl;
return 0;
}
如果不写using namespace std;为实现相同的效果,需要像这样书写代码。
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
return 0;
}
变量的位域
下面这段代码声明的是一个结构体中将一个字节拆分成多个变量来使用的过程。
#include <iostream>
using namespace std;
typedef unsigned char uint_8;
struct Switcher
{
uint_8 s1 : 1; // s1 only uses 1 bit in a uint_8
uint_8 s2 : 1; // s2 only uses 1 bit in a uint_8
uint_8 s3 : 1; // s3 only uses 1 bit in a uint_8
uint_8 s4 : 1; // s4 only uses 1 bit in a uint_8
uint_8 s5 : 1; // s5 only uses 1 bit in a uint_8
uint_8 s6 : 1; // s6 only uses 1 bit in a uint_8
uint_8 s7 : 1; // s7 only uses 1 bit in a uint_8
uint_8 s8 : 1; // s8 only uses 1 bit in a uint_8
};
int main()
{
Switcher s = {0, 0, 0, 0, 0, 0, 0, 1};
cout << (int)s.s8 << endl;
cout << sizeof(s) << endl;
return 0;
}
运行这段代码输出的结果是:
1
1
8个分别占一位的变量共用一个uint_8类型的内存,所以一共占用的内存为1字节。
指针
指针是一个数据类型,同时也是一个变量类型,它用于存储变量的地址,其声明方式如下。
Variable_Type * Pointer_Name;
^指向的变量类型 ^表示是个指针 ^指针的名称
例如:
int n_A;
float f_B;
bool b_C;
char c_D;
int * p_n_A;
// Integer Pointer p_n_A, refering to an [address] which [stores] value typeof int
float * p_f_B;
bool * p_b_C;
char * p_c_D;
p_n_A = &n_A;
// Getting Variable n_A's address and store it in p_n_A
p_f_B = &f_B;
p_b_C = &b_C;
p_c_D = &c_D;
在使用指针的过程中请注意:
不允许直接对指针进行赋值,也就是说,不允许访问未被允许访问的变量。
若需将指针初始化为空指针,请使用如下的代码。
// You can use this in Both C and C++
int * p_n_A = NULL;
// Or You can use this code below in C++
int * p_n_A = nullptr;
或者将指针初始化为已有变量的地址。
int a = 10;
int * pa = &a;
a += 1;
*pa += 1;
*(&a) += 1;
// The three lines of code shown above have the same function
对于数组变量而言,可以通过指针向后移动以实现遍历数组的效果,注释中的代码与其之前的那一行代码效果相同。
#include <iostream>
using namespace std;
int b[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int * pb = b;
// int * pb = &b[0];
int main()
{
for (int i = 0; i < 10; i++)
{
cout << *(pb + i) << endl;
// cout << *(b + i) << endl;
// cout << b[i] << endl;
// cout << *(&b[i]) << endl;
}
return 0;
}
这段代码的运行结果是:
0
1
2
3
4
5
6
7
8
9
那么,我们之前写的操作数组的函数,还可以像这样实现。
// Original
void v_Array_Show(const int a[], int n)
{
for (int i = 0; i < n; i++)
{
cout << a[i] << endl;
}
return;
}
// Use Pointer
void v_Array_Show(const int * a, int n)
{
for (int i = 0; i < n; i++)
{
cout << *(a + i) << endl;
}
return;
}
接下来是指向函数的指针。
#include <iostream>
using namespace std;
void v_SampleFunction(const int * a, int n);
const int SIZE = 10;
const int a[SIZE] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int main()
{
void (* v_p_FunctionPointer)(const int *, int) = v_SampleFunction;
v_p_FunctionPointer(a, SIZE);
return 0;
}
void v_SampleFunction(const int * a, int n)
{
for (int i = 0; i < n; i++)
{
cout << *(a + i) << endl;
}
return;
}
程序运行的结果为:
0
1
2
3
4
5
6
7
8
9
理解指针
pa[i][j] // Normal 2D Array
*(pa[i] + j) // Same as the statement above
*(pa + i)[j] // Same as the Statement above
*(*(pa + i) + j) // The value of (the Value of Pointer pa[i] (which SHOULD BE A POINTER) + j)
new关键字
手动申请内存并将申请的首地址返回。
int * pa = new int [10000];
delete关键字
将动态申请的内存释放。
delete [] pa;
通过new和delete用指针创建和删除一个二维数组
源代码如下,注意理解指向指针的指针的意思。
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ** pa = new char * [4];
memset(pa, 0, sizeof(pa) * 4);
for (int i = 0; i < 4; i++)
{
char * pb = new char [10];
pa[i] = pb;
memset(pa[i], 0, sizeof(char) * 10);
}
// Do Something
strcpy(pa[0], "Hello");
strcpy(pa[1], "kitty");
strcpy(pa[2], "Hello dog");
for (int i = 0; i < 4; i++)
{
cout << pa[i] << endl;
}
for (int i = 0; i < 4; i++)
{
if (pa[i])
{
delete [] pa[i];
pa[i] = NULL;
// pa[i] = nullptr;
}
}
if (pa)
{
delete [] pa;
pa = NULL;
//pa = nullptr;
}
return 0;
}
接下来是通过函数创建二维数组。
#include <iostream>
#include <cstring>
using namespace std;
void array_2dchar_init(char * * & pa, int row, int col);
void array_2dchar_show(char * * pa, int row);
void array_2dchar_del(char * * pa, int row);
int main()
{
char * * pa = NULL;
array_2dchar_init(pa, 4, 10);
strcpy(pa[0], "Hello");
strcpy(pa[1], "Kitty");
strcpy(pa[2], pa[0]);
strcpy(pa[3], "Dog");
array_2dchar_show(pa, 4);
array_2dchar_del(pa, 4);
return 0;
}
void array_2dchar_init(char * * & pa, int row, int col)
{
pa = new char * [row];
memset(pa, 0, sizeof(pa) * row);
for (int i = 0; i < row; i++)
{
char * pb = new char [col];
pa[i] = pb;
memset(pa[i], 0, sizeof(pa[i]));
}
return;
}
void array_2dchar_del(char * * pa, int row)
{
for (int i = 0; i < row; i++)
{
if (pa[i])
{
delete [] pa[i];
pa[i] = NULL;
}
}
if (pa)
{
delete pa;
pa = NULL;
}
return;
}
void array_2dchar_show(char * * pa, int row)
{
for (int i = 0; i < row; i++)
{
cout << pa[i] << endl;
}
return;
}
对于申请内存的内容的初始化。
int * p = new int;
*p = 2;
// The statement below is equal to the statements above.
int * p = new int(2);
int * p = new int{2};
// Same as the Statement above, Should be C++ 11 or Higher.
int * q = new int[7]{1, 2, 3, 4, 5, 6, 7};
// Should be C++ 11 or Higher.
相比如下这种代码,通过new关键字分配内存,会更加安全。
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int a[n];
return 0;
}
更加安全的分配方式为:
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int * a = new int[n];
while (!a)
{
a = new int[n];
}
if (a)
{
delete[] a;
a = nullptr;
}
return 0;
}
需要注意的是,类型需要一致。
struct point
{
double x, y;
};
int main()
{
point ** p1 = new point * [3];
// point (*p2)[3] = new point[2][3];
if (p)
{
delete [] p;
p = nullptr;
}
return 0;
}
同时,对于动态分配的内存,需要在不使用时进行释放,且在释放前,请不要改变通过new获得的地址,否则无法正确回收内存以致内存泄漏。
例题:
int n = 2;
int * a[] = {new int{n}, new int[2 * n]{4, 5, 6}, new int[2 * n]{1, 2, 3}};
// a[1][3] = 0
指向结构体的指针
主要要求了解如何通过指向结构体的指针输出其成员值。
#include <iostream>
using namespace std;
struct Person
{
char s_SN[21];
char s_Name[21];
int n_Year;
int n_Gender;
double d_Weight;
double d_Height;
int n_Score;
};
int main()
{
Person One = {"1234", "Kitty", 20, 0, 50.1, 174.1, 90};
cout << One.s_Name;
Person * Pa = & One;
strcpy(Pa -> s_Name, "jack");
cout<< Pa -> s_Name << endl;
return 0;
}
const 指针
对于const指针而言,需要明确的是两个内容: 到底是指向的变量是常量(不可更改),还是其指向的内存地址是常量(地址不可变动,但其所指向的内存地址中所存的值是可以改改的)
const int * p; // A Pointer Pointing to A Constant Integer [Integer CANNOT be CHANGED]
int const * p; // Same as the statement above
int * const p; // A Pointer Pointing to A Constant Memory Address [Integer Can be CHANGED]
同时,注意区分这两种指针,前者是指向数组的指针,后者是指针数组。
int * p[];
int (*p)[];
接下来是一段示例代码。
#include <iostream>
using namespace std;
char * cpy(char * Desti, char * Src)
{
char * Desti1 = Desti;
while (*Src)
{
*Desti1 = *Src;
Src++;
Desti1++;
}
*Desti1 = '\0';
return Desti;
}
int main()
{
char s_Desti[20], s_Src[] = "Sample String";
cout << cpy(s_Desti, s_Src) << endl;
return 0;
}
这个过程中,我们在编写函数时,可能对源字符串或源数据进行更改,这是我们不希望看到的。这个时候我们在参数上加上const关键字,以限定其为不可变更的变量,注意下面这一段代码与上一段代码的区别。
#include <iostream>
using namespace std;
char * cpy(char * Desti, const char * Src)
// You can change Src [Pointer], but cannot change *Src [Value]
{
char * Desti1 = Desti;
while (*Src)
{
*Desti1 = *Src;
Desti1++;
Src++;
}
*Desti1 = '\0';
return Desti;
}
int main()
{
char s_Desti[20], s_Src[] = "Sample String";
cout << cpy(s_Desti, s_Src) << endl;
return 0;
}
```c++
int * Function(int * p); // Consider this as Function 1
int * Function(const int * p); // Consider this as Function 2
int * Function(const int * p); // Consider this as Function 3
int * Function(int * const p); // Consider this as Function 4
// Function 2 and Function 3 ARE COMPLETELY THE SAME
// Funciton 1 and Function 4 Cannot appear in the same program
// Function 2 and Function 4 Can appear in the same program
在上面的代码中,Function 2和Function 3的函数名相同、参数表也完全相同,有二义性,是不合法的重载,Function 1和Function 4由于传参时无法区分是否为const,有二义性,也是不合法的重载,只有Function 2和Function 4是合法的重载。
链表
用图片来解释链表这种数据结构的话,就像这样(同时演示了节点的插入):
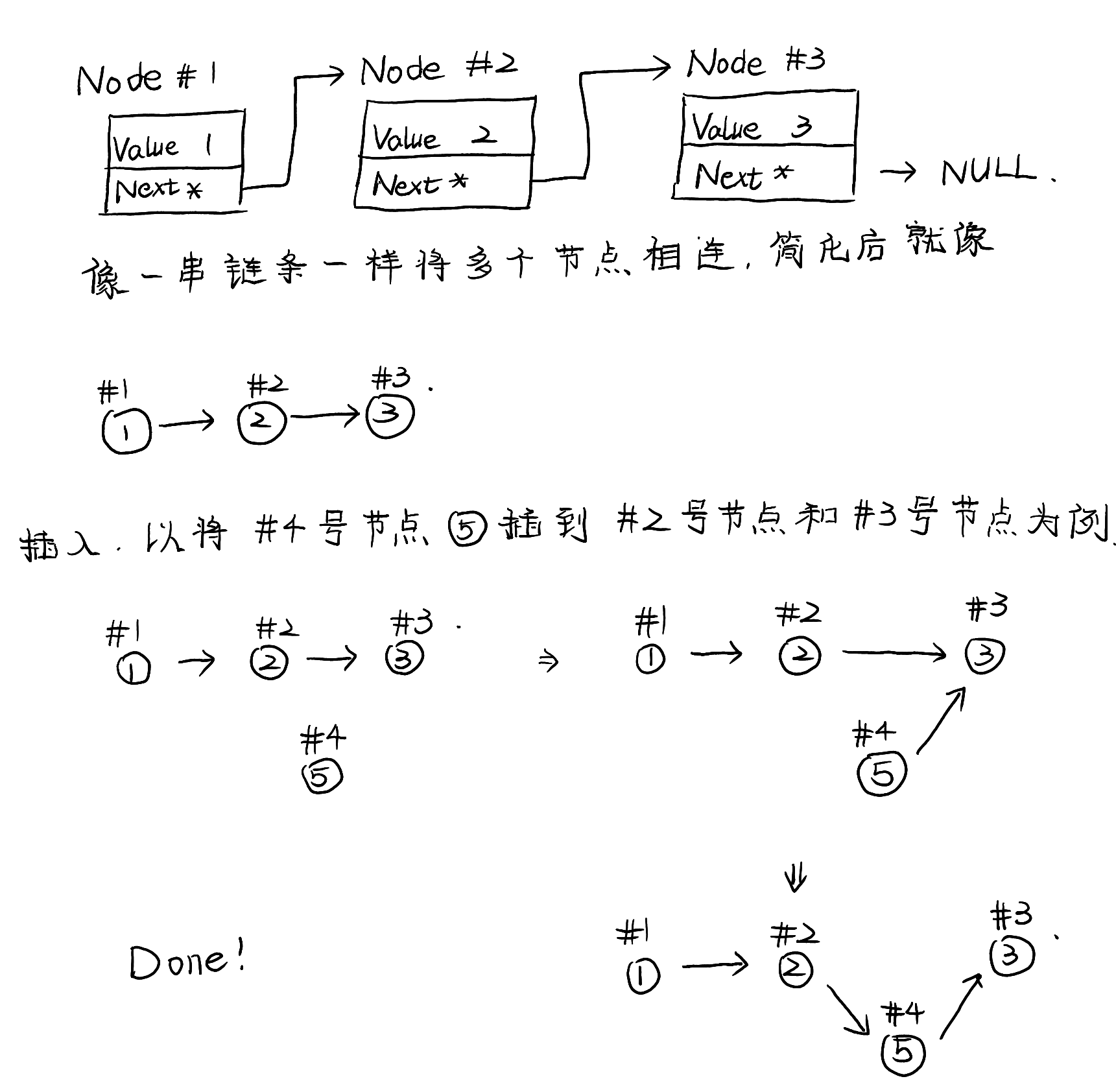
如果要进行删除或者排序,链表所执行的操作如下:
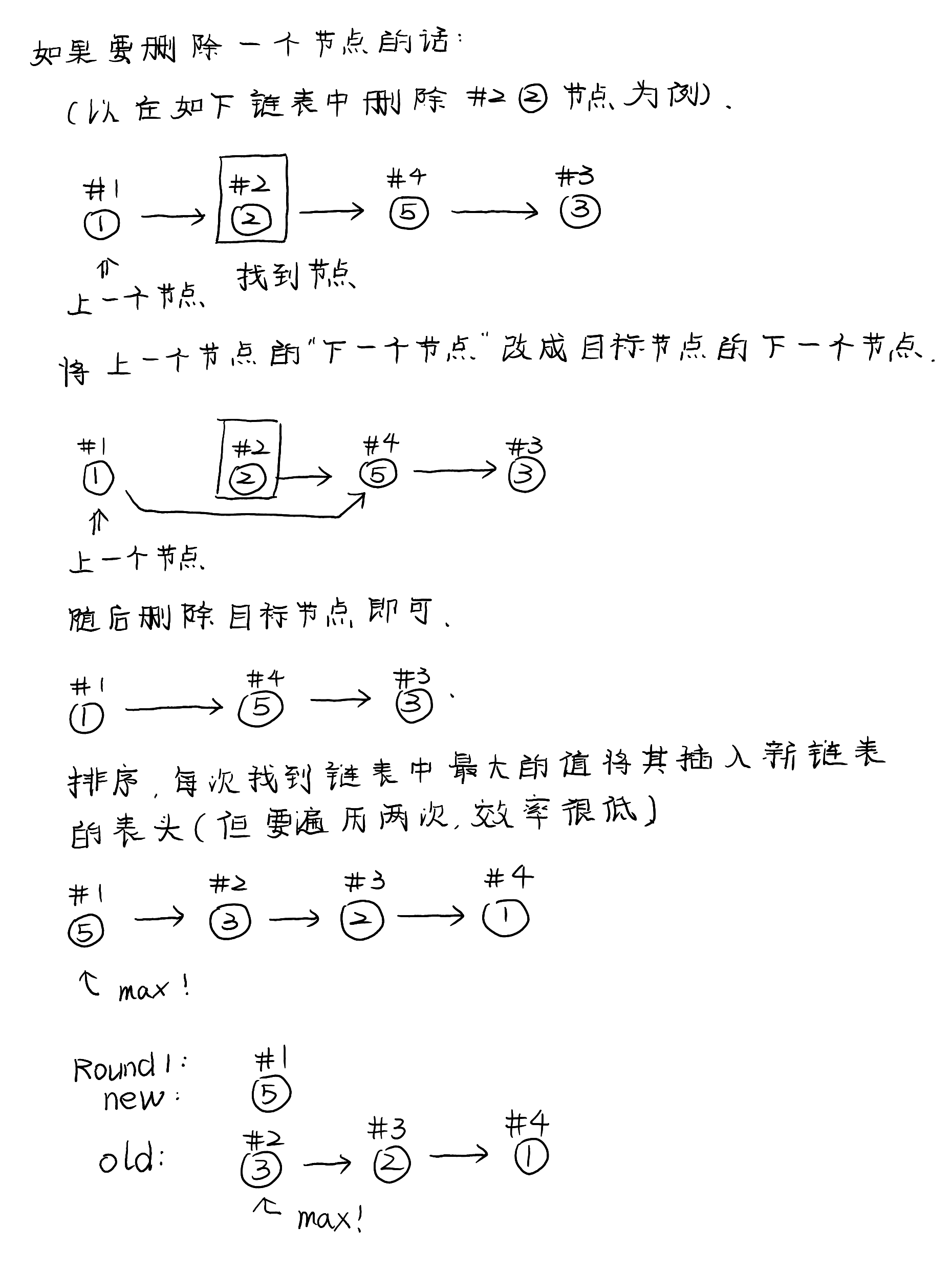
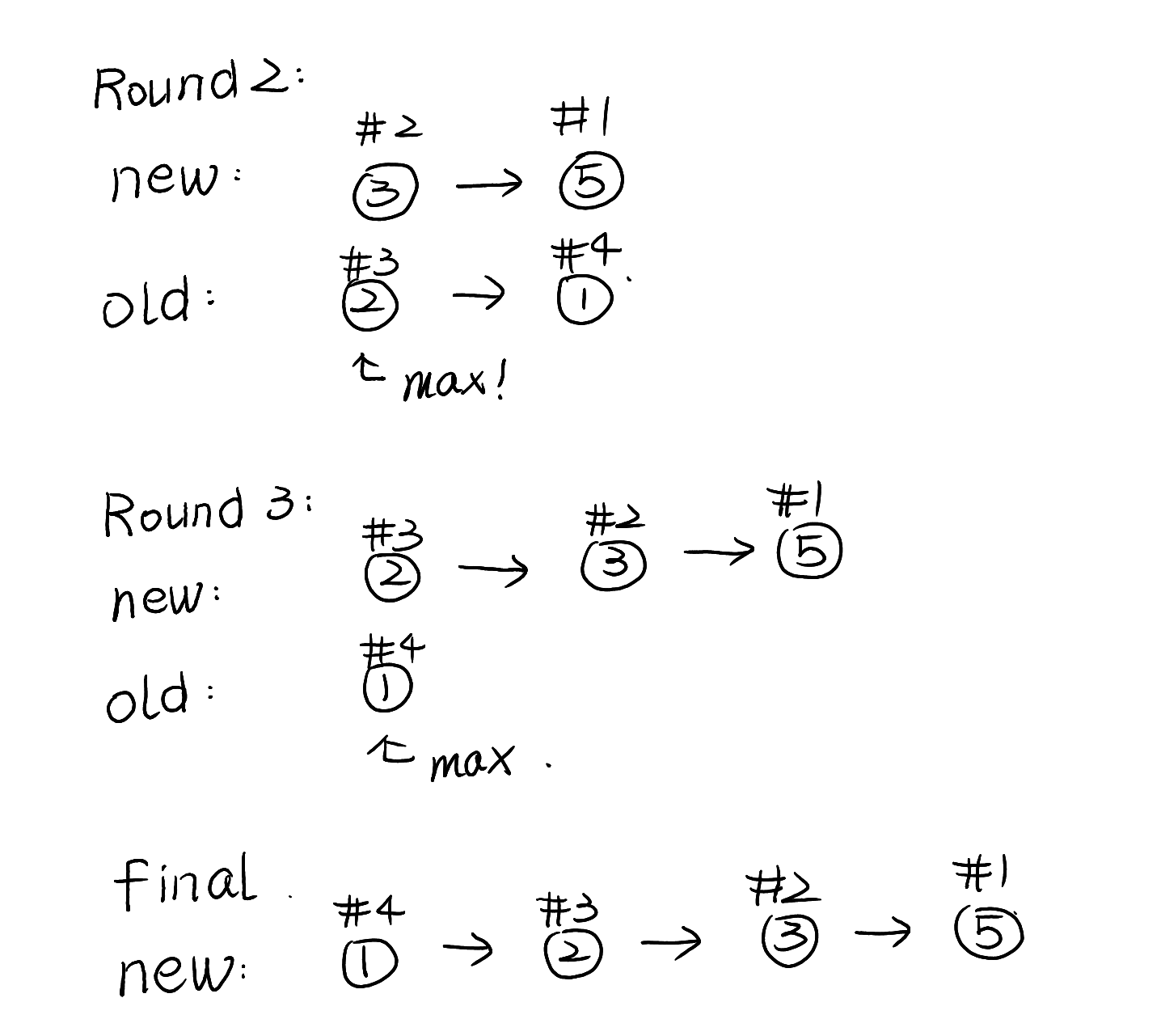
请看如下示例代码,这段代码用结构体Node存储节点的值,及下一个节点的指针,通过函数进行链表的建立、删除,节点的插入、删除。
#include <iostream>
using namespace std;
struct Node
{
int n_Value;
Node * p_Node_Next = NULL;
};
int n_TotNode;
int n_TargetNum;
int n_InputNum;
Node * p_Node_Start = NULL;
void v_Node_Insert(int n_CheckNum, int n_InsertNum);
void v_Node_Delete(int n_CheckNum);
void v_List_Create();
void v_List_Display();
void v_List_Delete();
int main()
{
v_List_Create();
v_List_Display();
cout << "Target Position for Insertion: ";
cin >> n_TargetNum;
cout << "The Inserted Number: ";
cin >> n_InputNum;
v_Node_Insert(n_TargetNum, n_InputNum);
v_List_Display();
cout << "Select a Number to Delete: ";
cin >> n_InputNum;
v_Node_Delete(n_InputNum);
v_List_Display();
v_List_Delete();
return 0;
}
void v_Node_Insert(int n_CheckNum, int n_InsertNum)
{
Node * p_Node_Add = new Node;
while (!p_Node_Add)
{
p_Node_Add = new Node;
}
p_Node_Add -> n_Value = n_InsertNum;
Node * p_Node_CheckNum = p_Node_Start;
int n_Flag_Found = 0;
while (p_Node_CheckNum)
{
if (p_Node_CheckNum -> n_Value == n_CheckNum)
{
n_Flag_Found = 1;
p_Node_Add -> p_Node_Next = p_Node_CheckNum -> p_Node_Next;
p_Node_CheckNum -> p_Node_Next = p_Node_Add;
break;
}
p_Node_CheckNum = p_Node_CheckNum -> p_Node_Next;
}
if (!n_Flag_Found)
{
cout << "Not Found the Requested Node" << endl;
if (p_Node_Add)
{
delete p_Node_Add;
p_Node_Add = NULL;
}
return;
}
cout << "Insert Successful" << endl;
return;
}
void v_Node_Delete(int n_CheckNum)
{
Node * p_Node_CheckNum = p_Node_Start;
Node * p_Node_TempLast = NULL;
int n_Flag_Found = 0;
while (p_Node_CheckNum)
{
if (p_Node_CheckNum -> n_Value == n_CheckNum)
{
n_Flag_Found = 1;
if (p_Node_CheckNum == p_Node_Start)
{
p_Node_Start = p_Node_CheckNum -> p_Node_Next;
}
else
{
p_Node_TempLast -> p_Node_Next = p_Node_CheckNum -> p_Node_Next;
}
if (p_Node_CheckNum)
{
delete p_Node_CheckNum;
p_Node_CheckNum = NULL;
}
break;
}
p_Node_TempLast = p_Node_CheckNum;
p_Node_CheckNum = p_Node_CheckNum -> p_Node_Next;
}
if (!n_Flag_Found)
{
cout << "Not Found the Requested Node" << endl;
return;
}
cout << "Deletion Successful" << endl;
return;
}
void v_List_Create()
{
cin >> n_TotNode;
Node * p_Node_Last = NULL;
for (int i = 0; i < n_TotNode; i++)
{
Node * p_Node_Create = new Node;
while (!p_Node_Create)
{
p_Node_Create = new Node;
}
if (!i)
{
p_Node_Start = p_Node_Create;
}
cin >> p_Node_Create -> n_Value;
if (i)
{
p_Node_Last -> p_Node_Next = p_Node_Create;
}
p_Node_Last = p_Node_Create;
}
return;
}
void v_List_Display()
{
Node * p_Node_CheckNum = p_Node_Start;
while (p_Node_CheckNum)
{
cout << p_Node_CheckNum -> n_Value;
if (p_Node_CheckNum -> p_Node_Next)
{
cout << " -> ";
}
p_Node_CheckNum = p_Node_CheckNum -> p_Node_Next;
}
cout << endl;
return;
}
void v_List_Delete()
{
Node * p_Node_CheckNum = p_Node_Start;
Node * p_Node_Temp = NULL;
while (p_Node_CheckNum)
{
p_Node_Temp = p_Node_CheckNum -> p_Node_Next;
if (p_Node_CheckNum)
{
delete p_Node_CheckNum;
p_Node_CheckNum = NULL;
}
p_Node_CheckNum = p_Node_Temp;
}
return;
}
需要注意的是,这段代码并未涉及将节点插入到链表开头的操作,如果需要将节点插入到链表开头,请参考下面这段代码:
Node * Node_Add = new Node;
while (!Node_Add)
{
Node_Add = new Node;
}
Node_Add -> n_Value = n_InsertValue;
Node_Add -> p_Node_Next = p_Node_Start -> p_Node_Next;
p_Node_Start = p_Node_Add;
老师的例程代码:
#include<iostream>
#include<cstring>
using namespace std;
/*
我党革命事业的成功,离不开千千万万战斗在隐秘战线的英雄们的付出。
在斗争最残酷的白色恐怖年代,我党隐秘战线上的同志们通过单线联系的方式传递情报,每一个情报员
仅仅知道其唯一下线是谁,一旦被捕,党组织可以迅速的将其从情报链条中剔除,
避免整个情报网遭受更大的损失;也可以在情报链的任何一个环节增加一名情报员,扩展链条长度;如果事态
变得不可挽回,组织也可以迅速解散整个情报链。
本题向默默奉献的红色特工(Red Intelligence Agent, RIA)致敬!
*/
/*以下内容为故事所需的枚举量*/
enum SocialRole
{
teacher, //老师
worker, //工人
soldier, //军人
official, //官员
others //其他
};
/*以下内容为故事所需的结构体*/
struct RIA
{
int level; //职位等级,在同一个情报链条上不允许重复
char rid[20]; //特工代号,在同一个情报链条上不允许重复
SocialRole sr; //社会角色
RIA * psub; //下线 subordinate
};
/*以下内容定义level 宏定义
数字越大表示层级越低,越靠近情报链的尾端
*/
#define LEVEL_TANGSENG 1
#define LEVEL_WUKONG 4
#define LEVEL_WUNENG 8
#define LEVEL_WUJING 10
#define LEVEL_NIUMOWANG 16
#define LEVEL_BAILONGMA 20
#define TEST_SHOW
/*以下内容为故事所需的函数声明*/
//新吸纳一名情报人员
RIA * CallRedIntelligenceAgent(int level, char* prid, SocialRole sr, RIA * psub = NULL);
//新建一条情报链
void CreateRedIntelligenceAgentList(RIA * &pLeader);
//内部从情报链中找到指定人员
RIA * FindThatColleague(RIA * pLeader, char * prid);
//情报链内新增一名情报人员,按照职位等级,插入到指定位置
void InsertNewRedIntelligenceAgent(RIA * &pLeader, RIA * pnewRIA);
//根据任务需要,从情报链中抽调一名同志
RIA * CallForAnotherWork(RIA * &pLeader, char * pColleague);
//情报链内除奸,干掉一名叛徒
void KillTraitor(RIA * &pLeader, char * ptraitorrid);
//有同志职位等级变动,重排序情报链
void Recombination(RIA * &pLeader);
//形势非常危急就地解散销毁资料潜伏
void DestroyAndLurk(RIA * &pLeader);
//解放了,信息公开了,让大家都认识他们吧
void ShowAllRIAs(RIA * pLeader, char * pmark);
//内联函数处理enum显示转换
inline void ShowSocialRole(SocialRole sr);
/*以下为故事的主要内容*/
int main(void)
{
//第一章:组织创建
//接到在南京建立情报战线的任务
RIA * pLeader = NULL;
//组织委派领导和部分同志到达南京,建立情报链
CreateRedIntelligenceAgentList(pLeader);
#ifdef TEST_SHOW
ShowAllRIAs(pLeader,"zu zhi chuang jian");
#endif
//第二章:牛魔王加入
//在南京又发展了一名下线,卖油条的个体户,代号牛魔王
RIA * pnew = CallRedIntelligenceAgent(LEVEL_NIUMOWANG,"niumowang",others);
//经过一段时间考察,领导谈话,将牛魔王吸纳进情报链
InsertNewRedIntelligenceAgent(pLeader,pnew);
#ifdef TEST_SHOW
ShowAllRIAs(pLeader,"niumowang jia ru");
#endif
//第三章:悟净升官
//经过几次考验,组织发现悟能表现没有悟净出色,决定给悟净升官
//悟净勤勤恳恳,工作出色,受到组织的提拔
RIA * pfind = FindThatColleague(pLeader,"wujing");
if(pfind)
{
pfind->level = LEVEL_WUNENG - 1;
//悟净升职了,需要重排序情报链关系
Recombination(pLeader);
}
#ifdef TEST_SHOW
ShowAllRIAs(pLeader,"wujing sheng guan");
#endif
//第四章:论功行赏
//抗日战争任务圆满完成,组织论功行赏
ShowAllRIAs(pLeader,"lun gong xing shang");
//第五章:悟能之死
//随着蒋介石撕毁停战协定,大肆残害我党人员,有些同志害怕了,悟能叛变,锄奸小队行动了
KillTraitor(pLeader, "wuneng");
#ifdef TEST_SHOW
ShowAllRIAs(pLeader,"wuneng bei sha");
#endif
//第六章:组织潜伏
//随着白色恐怖的加剧,情报战线受到严重损毁,组织决定暂时潜伏,等待再次激活,为国效力。
DestroyAndLurk(pLeader);
#ifdef TEST_SHOW
ShowAllRIAs(pLeader,"zu zhi qian fu");
#endif
return 0;
}
/*以下内容为故事所需的函数定义*/
//新吸纳一名情报人员
RIA * CallRedIntelligenceAgent(int level,char* prid, SocialRole sr, RIA * psub)
{
RIA * pnew = new RIA;
pnew->level = level;
strcpy(pnew->rid,prid);
pnew->sr = sr;
pnew->psub = psub;
return pnew;
}
//新建一条情报链
void CreateRedIntelligenceAgentList(RIA * &pLeader)
{
RIA * pnew = CallRedIntelligenceAgent(LEVEL_WUKONG,"wukong",teacher);
InsertNewRedIntelligenceAgent(pLeader,pnew);//插入表头
pnew = CallRedIntelligenceAgent(LEVEL_WUJING,"wujing",worker);
InsertNewRedIntelligenceAgent(pLeader,pnew);//插入表尾
pnew = CallRedIntelligenceAgent(LEVEL_WUNENG,"wuneng",official);
InsertNewRedIntelligenceAgent(pLeader,pnew);//插入表间
pnew = CallRedIntelligenceAgent(LEVEL_TANGSENG,"tangseng",soldier);
InsertNewRedIntelligenceAgent(pLeader,pnew);//插入表头
pnew = CallRedIntelligenceAgent(LEVEL_BAILONGMA,"bailongma",others);
InsertNewRedIntelligenceAgent(pLeader,pnew);//插入表尾
}
//从情报链中找到指定人员
RIA * FindThatColleague(RIA * pLeader, char * prid)
{
RIA * pfind = pLeader;
while(pfind){
if(0 == strcmp(pfind->rid,prid)){
break;
}
pfind = pfind->psub;
}
return pfind;
}
//情报链内新增一名情报人员,按照职位等级,插入到指定位置
void InsertNewRedIntelligenceAgent(RIA * &pLeader, RIA * pnewRIA)
{
RIA * pinsert = pLeader;
while(pinsert)
{
if(pnewRIA->level < pinsert->level)
{
break;
}
pinsert = pinsert->psub;
}
if(pinsert == pLeader)
{//插入头部
pnewRIA->psub = pLeader;
pLeader = pnewRIA;
}
else if(pinsert == NULL)
{//插入尾部
pinsert = pLeader;
while(pinsert->psub)
pinsert = pinsert->psub;
pinsert->psub = pnewRIA;
pnewRIA->psub = NULL;
}
else
{//插入中间位置
RIA * pfront = pLeader;
while(pfront->psub != pinsert)
pfront = pfront->psub;
pnewRIA->psub = pinsert;
pfront->psub = pnewRIA;
}
}
//根据任务需要,从情报链中抽调一名同志
RIA * CallForAnotherWork(RIA * &pLeader, char * pColleague)
{
RIA * pfind = FindThatColleague(pLeader, pColleague);
if(pfind == pLeader)
{//头部剔除
pLeader = pLeader->psub;
}
else
{//尾部和中间剔除
RIA * pend = pLeader;
while(pend->psub != pfind)
pend = pend->psub;
pend->psub = pfind->psub;
}
return pfind;
}
//情报链内除奸,干掉一名叛徒
void KillTraitor(RIA * &pLeader, char * ptraitorrid)
{
RIA * pfind = CallForAnotherWork(pLeader, ptraitorrid);
delete pfind;
}
//有同志职位等级变动,重排序情报链
void Recombination(RIA * &pLeader)
{
RIA * pold = NULL;
RIA * ptmpLeader = NULL;
while(pLeader)
{
pold = CallForAnotherWork(pLeader,pLeader->rid);
InsertNewRedIntelligenceAgent(ptmpLeader,pold);
}
pLeader = ptmpLeader;
}
//形势非常危急就地解散销毁资料潜伏
void DestroyAndLurk(RIA * &pLeader)
{
RIA * pdes = pLeader;
while(pLeader)
{
pdes = pLeader;
pLeader = pLeader -> psub;
delete pdes;
}
}
//解放了,信息公开了,让大家都认识他们吧
void ShowAllRIAs(RIA * pLeader, char * pmark)
{
cout<<"*********** "<<pmark<<" *********\n";
RIA * pshow = pLeader;
while(pshow){
cout<<pshow->level<<" "<<pshow->rid<<" ";
ShowSocialRole(pshow->sr);
cout<<endl;
pshow = pshow->psub;
}
}
//内联函数处理enum显示转换
inline void ShowSocialRole(SocialRole sr)
{
switch(sr){
case teacher:
cout<<"teacher";
break;
case worker:
cout<<"worker";
break;
case soldier:
cout<<"soldier";
break;
case official:
cout<<"official";
break;
case others:
cout<<"others";
break;
default:
cout<<"unknown";
}
}
例题选讲
[Pg. 85] 例4.11
写法不唯一,可用于参考思路。
#include <iostream>
using namespace std;
int a;
int main()
{
cin >> a;
while (a) // 等效于 while(a != 0)
{
if (a < 0)
{
cout << "Invalid Input, Please Input A POSITIVE Integer." << endl;
cin >> a;
continue;
}
while (a)
{
cout << a % 10;
a /= 10;
}
cout << endl;
cin >> a;
}
return 0;
}
[Pg. 86] 例4.12
写法不唯一,可用于参考思路。
#include <iostream>
using namespace std;
int main()
{
for (int i = 1; i <= (100 / 5); i++)
{
for (int j = 1; (5 * i) + (3 * j) <= 100; j++)
{
for (int k = 3; (5 * i) + (3 * j) + (k / 3) <= 100; k += 3)
{
if ((5 * i + 3 * j + k / 3 == 100) && (i + j + k == 100))
{
cout << i << ' ' << j << ' ' << k << endl;
}
}
}
}
return 0;
}
(暴力枚举答案)
[Pg. 143] 例6.2
多项式的计算。
给定多项式$y=5x^5-3.2x^3+2x^2+6.2x-8$,输入$x$,求$y$。
考虑$y=5x^5+0\times x^4-3.2x^3+2x^2+6.2x-8x^0 = ((((5x + 0)x-3.2)x+2)x+6.2)x-8$
逐层向外进行展开即可得到答案。
#include <iostream>
using namespace std;
double Multiplier[6] = {5, 0, -3.2, 2, 6.2, -8};
double Result = Multiplier[0];
double Input;
int main()
{
cin >> Input;
for (int i = 0; i < 5; i++)
{
Result = Result * Input + Multiplier[i + 1];
}
cout << Result;
return 0;
}
习题课
习题4_11_1
思路:利用位运算,逐次将高位向低处移动后进行输出。
(上课讲的方法对负数是直接输出原码)
#include <iostream>
using namespace std;
int main()
{
int a;
cin >> a;
if(a < 0)
{
cout << '-';
a *= -1;
}
for (int i = 31; i >= 0; i--)
{
cout << (a >> i & 0x01);
// 将a向右移i位,并只取最低一位输出
}
cout << endl;
return 0;
}
(如果我就是要输出负数的补码呢?)
#include <iostream>
using namespace std;
int main()
{
int a;
cin >> a;
for (int i = 31; i >= 0; i--)
{
cout << (a >> i & 0x01);
// 将a向右移i位,并只取最低一位输出
}
cout << endl;
return 0;
}
思考为什么省掉对负数的判断后,负数就会正常输出补码。
习题4_11_2
思路:与上一题类似,右移位数改成4,初始位数改为28。
#include <iostream>
using namespace std;
int main()
{
int a;
cin >> a;
if(a < 0)
{
cout << '-';
a *= -1;
}
cout << "0x";
for (int i = 28; i >= 0; i -= 4)
{
int tmp = (a >> i & 0x0f);
switch(tmp)
{
case 15:
cout << 'f';
break;
case 14:
cout << 'e';
break;
case 13:
cout << 'd';
break;
case 12:
cout << 'c';
break;
case 11:
cout << 'b';
break;
case 10:
cout << 'a';
break;
default:
cout << tmp;
break;
}
}
return 0;
}
(这个时候就有同学要问了,这么多条件枚举出来,不是很麻烦吗?)
我们再来看看用if的写法:
#include <iostream>
using namespace std;
int main()
{
int a;
cin >> a;
if(a < 0)
{
cout << '-';
a *= -1;
}
cout << "0x";
for (int i = 28; i >= 0; i -= 4)
{
int tmp = (a >> i & 0x0f);
if (tmp >= 0 && tmp < 10)
{
cout << tmp;
}
else
{
cout << (char)(tmp - 10 + 'a');
}
}
return 0;
}
这里最妙的是什么呢?利用char类型存储ASCII码值时,可通过增加字母之间的差值来得到对应的字符。
也就是这里:
(char)(tmp - 10 + 'a')
习题4_11_3
在计算机中,数值的表示是有上限的,当加、减、乘超出这个上限,出现的溢出现象是不可控的。
我们原本判定是否会溢出最大值的方式是检查$Current \times i > MAX$是否成立,成立则说明已经到达最大值。
但考虑到运算过程中的溢出问题,$Current \times i$即便溢出也无法正确表达。
既然乘会溢出,那么我们不妨反过来,用不等式两侧同时除以$i$以达到相同效果。
也就是:$Current > \frac{MAX}{i}$
对应的代码实现就是(这里使用的是int,对于long long来说同理):
#include <iostream>
using namespace std;
int main()
{
unsigned int MAX = 0xffffffff;
unsigned int x = 1;
unsigned int n = 1;
while(1)
{
if (MAX / x < n)
{
cout << "x=" << x << endl;
cout << "n=" << n << endl;
break;
}
x = x * n;
n++;
}
return 0;
}
习题4_11_4
这里的问题是如何解决输入字符的问题。
这里我们使用char存储读入的字符,并对其进行判断。
#include <iostream>
using namespace std;
int main()
{
char ch;
int count = 0;
while(1)
{
cin >> ch;
if (ch == 'q')
{
cout << count << endl;
break;
}
if (ch >= '0' && ch <= '9')
{
count++;
}
}
return 0;
}
习题4_11_5
思路同4_11_3,具体实现略。
习题4_11_6
使用求根公式,注意判断是不是方程,以及是不是二次方程,考察if-else语句
习题4_11_7
注意临时变量的使用。
#include <iostream>
using namespace std;
int main()
{
int a = 1;
int b =2;
cout << a << '/' << b << ' ';
a += 2;
for (int i = 0; i < 19; i++)
{
cout << a << '/' << b << ' ';
int tmp = b;
b = a;
a = a + tmp;
}
return 0;
}
习题4_11_8
对于一个整数而言,最简单的方式就是从1开始枚举尝试去除这个数以得到这个数的所有因子,由于该题数据规模较小,不需要对其进行剪枝,所以可以有这样的代码。
#include <iostream>
using namespace std;
int main()
{
for (int n = 2; n < 101; n++)
{
int sum = 0;
for (int i = 1; i < n; i++)
{
if (n % i == 0)
{
sum += i;
}
}
if (sum == n)
{
cout << n << endl;
}
}
}
习题4_11_9
使用while循环,对于每次兑换都更新瓶盖数和瓶子数。
#include <iostream>
using namespace std;
int main()
{
int money = 10;
// cin >> money;
int pin = money / 2;
int pingz = pin;
int gaiz = pin;
while (1)
{
if(pingz < 2 && gaiz < 4)
{
cout << pin << endl;
break;
}
int newpin = 0;
newpin += pingz / 2;
pingz %= 2;
newpin += gaiz / 4;
gaiz %= 4;
pingz += newpin;
gaiz += newpin;
pin += newpin;
}
return 0;
}
习题5_21_5
本题是在MOOC上的一道题,其对时间复杂度有要求,如果按照上课的写法提交,会得到运行时间超时的结果,请注意。
时间限制: 500ms
[题目描述]
设计一个程序,对于输入的任意一个正整数$x$,分解质因数,并且按从小到大的次序输出所有的质因数。
[输入描述]
一个正整数$x$
[输出描述]
按$x=x_1x_2x_3\dotsx_n$的格式输出
[样例输入]
6
[样例输出]
6=2*3
上课时的例程代码:
// File: MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
bool is_Prime(int n);
void show_prime_factors(int n);
#endif
// File: MyFunction.cpp
#include "MyFunction.h"
#include <cmath>
#include <iostream>
using namespace std;
bool is_Prime(int n)
{
if (n <= 1)
{
return false;
}
if (n == 2 || n == 3 || n == 5 || n == 7)
{
return true;
}
else
{
int i;
int tmp = sqrt(n) + 1;
for (i = 2; i <= tmp; i++)
{
if (!(n % i))
{
return false;
}
}
if (i > tmp)
{
return true;
}
}
}
void show_prime_factors(int x)
{
cout << x << '=';
unsigned int tmp = x / 2 + 1;
bool isfirst = false;
for (int i = 2; i <= tmp; i++)
{
if (!(is_Prime(i)))
{
continue;
}
while(1)
{
if (x % i)
{
break;
}
if (isfirst == false)
{
cout << i;
isfirst = true;
}
else
{
cout << '*' << i;
}
x /= i;
}
}
}
//File: main.cpp
#include <iostream>
#include "MyFunction.h"
using namespace std;
int main()
{
unsigned int x = 0;
cin >> x;
show_prime_factors(x);
return 0;
}
然而这个算法在遇到超过$500000000$的素数(甚至更小)时,运行时间会超过$500$ms的限制,因为程序在运行的过程中,1秒运行的次数约为$1000000000$(即$10^9$)次,这样反复运行,可能会导致超时,思考应该如何解决这个问题。
不如换个角度想一想,如果这个数一开始就是质数,那我们用一个循环把它以下的所有数全判一遍是不是质数肯定非常浪费时间。
那么,我们要怎么改呢?
在MOOC上的这道题中,有这样的一句提示:
创建void FacPrimely(int n)函数,如果已经找到$n$的一个质因数$k$,那就把这个质因数$k$输出,并再去找$n/k$的质因数,也就是使用递归的方式完成这道题。
不妨看看这样的代码:
#include <iostream>
using namespace std;
void FacPrimely(int n);
int main()
{
int n;
cin >> n;
cout << n << '=';
FacPrimely(n);
return 0;
}
void FacPrimely(int n)
{
/* If The Number input is 1, that means all factors of
this number has been found, thus we return directly to
show the process is all done.*/
if (n == 1)
{
return;
}
/* If The Number is Even, it's definitely dividable by 2,
So we divide the Number Repeatedly until it cannot be
divided by 2, resulting in a odd number.*/
if (!(n % 2))
{
while (!(n % 2))
{
n /= 2;
cout << 2;
if (n != 2)
{
cout << '*';
}
}
FacPrimely(n);
return;
}
/* If The Program runs here, n is an odd number for sure,
all we have to do here is to just check if it's dividable
by some smaller odd number. And if there is none, it's a
prime number, we output itself.
*/
for (int i = 3; i <= n / i; i += 2)
{
if (!(n % i))
{
cout << i << '*';
FacPrimely(n / i);
return;
}
}
cout << n;
return;
}
这里展示了一份使用递归方式完成这道题,且不会超时的代码。
首先我们检查传入的数是否是1,如果是1,说明我们的质因数分解已经结束,直接返回。
当传入的数不是1时,我们检查这个数是否是偶数,如果是偶数,那么其一定存在质因数2,那我们就反复除以2,直到它不再是偶数为止,将不再是偶数的因子传到下一次检查中。
当传入的数$n$既不是1,也不是偶数,那一定就是奇数,对于奇数我们只需要从$3$到$\sqrt{n}$对其检查其是否有奇数因子既可。
注意这里的写法,思考为什么这里是i <= n / i而不是i * i <= n呢?
思考:我们为什么不去检查这个奇数因子是否是质数?
因为我们的检查是从小到大依次检查,如果一个奇数不是质数,那它一定已经被之前检查到的更小的奇数因子分解掉了,所以我们检查到的奇数因子一定是质数。如果检查到的奇数因子能整除被检查的数,那它就是我们要找的质因数。
最后,如果我们从$3$到$\sqrt{n}$检查了所有的奇数因子都没法整数$n$,那么很显然,$n$是一个质数,那输出其本身即可,分解完毕。
如果不是因为题目中限定了FacPrimely(int n)只有一个参数,这份代码在运行效率上还可以再做提升,留作思考。
习题5_21_6
[题目描述]
编写一个函数int getrev(int n),对一个正整数$n$返回其反序数。反序数就是各个位置的数颠倒过来组成的正整数,例如$123$的反序数是$321$,$120$的反序数是$21$。进一步,如果一正整数$n$的反序数就是它自己,如$2$,$33$,$121$,该数$n$就是回文数。编写一个函数bool ishw(int n)判断$n$是否为回文数。
有一个数学猜想:对任一正整数$n$,且$n$不是回文数,先得到其反序数$n’$,再与原数$n$相加,即n+=n',得到一个新的数。如此重复若干次,$n$就是一个回文数。
编写程序验证是否正确,并输出过程及步数。
[输入描述]
一个正整数$x$
[输出描述]
按$n_2=n_1+n_1’$的格式输出,并输出总步数。
[样例输入]
12
[样例输出]
33=12+21
1
这是上课时的例程代码:
我们以工程的形式呈现这个项目,这里我们新引进一个内容,叫typedef,即将一种变量类型进行重命名,比如下面代码中的typedef char int_8;即使用int_8来替代char作为类型名称,这样的好处是我们可以通过自己的方式知道这个变量的位数(换言之,其所占内存的大小)来更好地判断越界问题。
// File: MyFunction.h
#ifndef __MYFUNCTION_H__
#define __MYFUNCTION_H__
typedef char int_8 ;
typedef short int_16 ;
typedef int int_32 ;
typedef unsigned char uint_8 ;
typedef unsigned short uint_16;
typedef unsigned int uint_32;
int getrev(uint_32 n);
bool ishw(uint_32 n);
void provehw(uint_32 n);
#endif
// File: MyFunction.cpp
#include "MyFunction.h"
#include <iostream>
using namespace std;
int getrev(uint_32 n)
{
uint_32 inver = 0;
while(n)
{
inver = inver * 10 + n % 10;
n /= 10;
}
return inver;
}
bool ishw(uint_32 n)
{
return n == getrev(n);
}
void provehw(uint_32 n)
{
uint_32 tmp = n;
uint_32 count = 0;
while(1)
{
if(ishw(tmp))
{
break;
}
uint_32 inver = getrev(tmp);
cout << tmp + inver << '=' << tmp << " " << inver << endl;
tmp += inver;
count++;
}
cout << count << endl;
}
// File: main.cpp
#include "MyFunction.h"
#include <iostream>
using namespace std;
int main()
{
uint_32 x;
cin >> x;
provehw(x);
return 0;
}
用单文件项目的写法如下:
#include <iostream>
using namespace std;
int getrev(int n);
bool ishw(int n);
int main()
{
int n;
int tmp;
int cnt = 0;
cin >> n;
while(!ishw(n))
{
tmp = getrev(n);
cout << n + tmp << '=' << n << '+' << tmp << endl;
n += tmp;
cnt++;
}
cout << cnt << endl;
return 0;
}
int getrev(int n)
{
int ret = 0;
while(n)
{
ret = ret * 10 + n % 10;
n /= 10;
}
return ret;
}
bool ishw(int n)
{
return n == getrev(n);
}